
なぜ今「AIのコスト」を知るべきなのか
2026年2月、中国の Zhipu AI が GLM5 をリリースしました。注目すべきは、このモデルが NVIDIA 製 GPU ではなく Huawei Ascend チップ で学習されたという点です1。背景には、米国による NVIDIA 製 GPU の輸出規制があります。NVIDIA は2026年Q1に中国向け GPU 供給を 30% 削減 すると発表し2、AI開発に必要な計算資源の確保がますます困難になっています。
一方、Anthropic CEO の Dario Amodei は「現在学習中のモデルは $1B(約1,500億円)に迫るコストがかかっており、2027年には $10B〜$100B に達する可能性がある」と述べています3。AIモデルの学習と運営には、想像を超えるコストが発生しているのです。
この記事では、AIデータセンターの運営コストを MECE(Mutually Exclusive, Collectively Exhaustive) の原則で漏れなく分解し、公開データと フェルミ推定 を組み合わせてその実態を明らかにします。
この記事の読み方: 公開データがある箇所はソース付きで事実提示し、非公開の箇所は「フェルミ推定」とラベルを明示して推定しています。
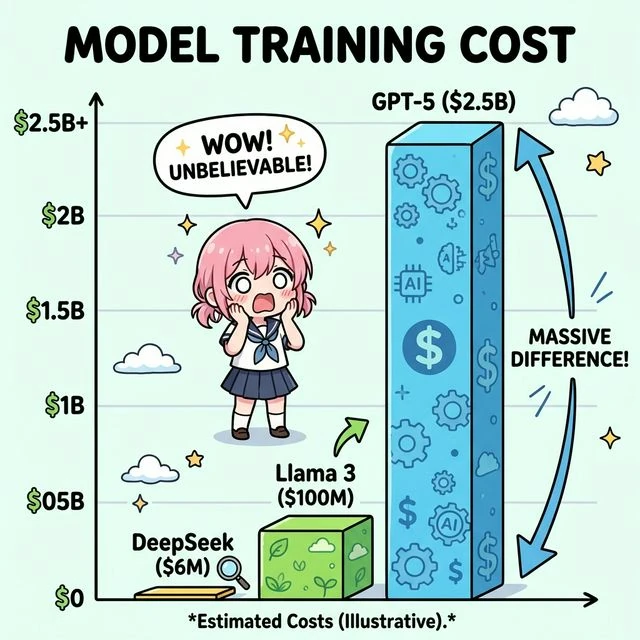
フラグシップモデルの学習コスト比較
最新のフラグシップAIモデルはいくらで学習されたのか。クローズドモデルとオープンウェイトモデルを分けて見ていきます。
クローズドモデル
GPT-5(OpenAI): HSBCの推定によると、GPT-5の学習コストは $1.7B〜$2.5B(約2,500億〜3,800億円)とされています4。6ヶ月間の学習ランでコンピュート費用だけで $500M(約750億円)を超えるとの報告もあります5。
Gemini 1.0 Ultra(Google): 学習コストは約 $192M(約290億円)と推定されています6。ただし、Google の2026年度 AI 設備投資予算は $175B〜$185B に達しており、後続モデル(Gemini 3 Pro 等)のコストはこの数字に含まれていると見られます7。
Claude 3(Anthropic): 学習コストは「数千万ドル」級と報告されています8。後続の Opus 4.5、Opus 4.6 はさらに高額と推定されますが、具体的な金額は非公開です。
オープンウェイトモデル
Llama 3.1 405B(Meta): 最大 16,000 基の H100 を使用し、約 30.8M GPU 時間を要しました。学習コストは $92.4M〜$123.2M(約140億〜185億円)と推定されています9。Meta は2026年の設備投資として $115B〜$135B を計画しており、2025年末までに 130万基の GPU を運用する方針です10。
DeepSeek V3: 約 2.788M H800 GPU 時間 で学習。H800 の時間単価 $2 で計算すると、学習コストは約 $5.6M(約8.4億円)と驚異的に低コストです11。ただしこの金額は「公式の学習ラン」のみであり、事前研究・アブレーション実験・インフラ費用は含まれません。サーバー CAPEX を含めた総投資は約 $1.6B との分析もあります12。MoE アーキテクチャ(671B パラメータ中 37B がアクティブ)や FP8 混合精度学習の採用が、Llama 3 405B の 約 1/11 の GPU 時間 という効率性を実現しています13。
GLM5(Zhipu AI): NVIDIA 製 GPU を使わず、 Huawei Ascend チップ と MindSpore フレームワークで学習された初の主要フラグシップモデルです。Moore Threads、Cambricon、Kunlun Chip など中国産チップ6社でのデプロイにも対応しています14。具体的な学習コストは非公開ですが、「脱 NVIDIA」の象徴的事例として注目されています。
学習コスト比較テーブル
| モデル | パラメータ | GPU構成 | 推定学習コスト | 備考 |
|---|---|---|---|---|
| GPT-5 | 非公開 | 非公開 | $1.7B〜$2.5B | HSBC推定 |
| Gemini Ultra | 非公開 | TPU v4/v5 | $192M | コンピュートのみ |
| Claude 3 | 非公開 | 非公開 | 数千万ドル級 | 後続は $1B 級 |
| Llama 3.1 405B | 405B | H100 ×16,000 | $92.4M〜$123.2M | 30.8M GPU時間 |
| DeepSeek V3 | 671B (37B active) | H800 ×2,048 | $5.6M | 学習ランのみ |
| GLM5 | 非公開 | Ascend | 非公開 | Huaweiチップ |
注意: 「学習コスト」の定義は各社で異なります。コンピュート費用のみ、研究開発全体、インフラ含む──どの範囲を指すかで金額は大きく変わります。
データセンター運営コストの MECE 分解
AIデータセンターの運営コストを、漏れなく・重複なく6つのカテゴリに分解します。100MW(メガワット)級の大規模 AI データセンターをモデルケースとして、年間運営コスト $475M〜$974M(約710億〜1,460億円)の内訳を見ていきましょう15。
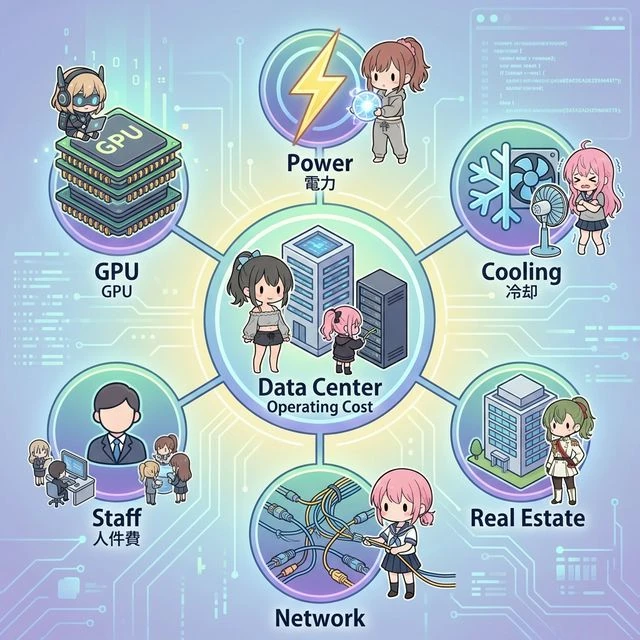
① GPU / ハードウェア(コスト支配的)
AIデータセンターの最大のコストドライバーです。
- NVIDIA H100: 単体 $25,000〜$40,000。8GPU サーバーシステムで $200K〜$450K16
- NVIDIA B200: 単体 $30,000〜$50,000。DGX B200 システムで約 $515K。NVL72(72基搭載ラック)は $2M〜$3M17
- ハードウェアリフレッシュ: 100MW 施設で1サイクルあたり $800M 超15
- 市場規模: データセンター GPU 市場は2025年に $96.5B。2026年の世界 AI チップ市場は $500B に迫る見通し18
B200 の製造原価は $5,700〜$7,300 と推定されており、$30,000〜$40,000 の販売価格との間には大きなマージンがあります19。HBM(高帯域メモリ)と先端パッケージングが製造コストの大部分を占めています。
② 電力コスト(全体の 40〜60%)
電気代はデータセンター運営費の 40%〜60% を占める最大の経常コストです20。
- 100MW 施設: 年間電気代 $61M〜$88M(約92億〜132億円)15
- 世界 DC 電力消費: 2022年 460 TWh → 2026年予測 約 1,050 TWh(2.3倍)21
- 米国 DC 電力需要: 2025年 61.8 GW → 2026年 75.8 GW22
- 一部地域ではデータセンター活動により電気代が 5年で 267% 上昇23
米国の総電力消費に占めるデータセンターの割合は、2023年の 4.4% から2028年には 6.7%〜12% に拡大する見通しです24。
③ 冷却コスト(全体の 30〜40%)
AIチップの高発熱により、冷却は「サイレント・タックス」と呼ばれるほど大きなコスト要因です。
- データセンター総エネルギー使用の 30%〜40% を占める25
- AI 最適化ラックは 30kW〜100kW 超/ラック の電力密度(従来サーバーの5〜10倍)
- 直接液冷市場 は 2030年までに $8B 超 に成長予測26
- 大規模 AI データセンターは1日あたり最大 500万ガロン の水を消費27
- PUE(電力使用効率): 業界平均 1.58、Google の一部施設で 1.0828
④ 人件費(全体の 20〜25%)
データセンター運営予算の約 20%〜25% は人件費です20。高度なスキルを持つ SRE(サイトリライアビリティエンジニア)、セキュリティ専門家、ネットワークエンジニアの人件費が含まれます。AI 特化施設では ML エンジニアやデータサイエンティストも必要です。
⑤ ネットワーク・ストレージ
学習クラスタでは GPU 間の高速通信が不可欠です。InfiniBand や NVLink による高帯域・低遅延のネットワーク接続が必要であり、ペタバイト級のデータストレージも求められます。大規模モデルの学習データは数十〜数百TBに達し、チェックポイントの保存にも膨大なストレージが必要です。
⑥ 施設・不動産
土地の取得・建設費用、冗長電源(UPS、発電機)、物理的セキュリティ、光ファイバー接続のインフラ整備など。大規模施設の建設には数十億ドル規模の初期投資が必要です。
コスト構造の全体像
| カテゴリ | コスト比率(推定) | 主な内容 |
|---|---|---|
| ① GPU/ハードウェア | 30〜40% | GPU購入、サーバー、リフレッシュ |
| ② 電力 | 25〜35% | 電気代(IT機器 + 冷却) |
| ③ 冷却 | 10〜15% | 空調・液冷・水消費 |
| ④ 人件費 | 10〜15% | 運用・セキュリティ・ML人材 |
| ⑤ ネットワーク・ストレージ | 5〜10% | InfiniBand、ストレージ |
| ⑥ 施設 | 5〜10% | 不動産、建設、冗長電源 |
Note: 冷却コスト(③)の電力消費分は ②電力コスト に含まれるため、上記比率は「設備投資+運営費」をベースに分離しています。MECE の原則上、エネルギーコストの二重計上を避けるため、②は「IT機器 + 冷却の電気代合計」、③は「冷却設備の資本コストと保守」として分離しています。
フェルミ推定──GPT-5 の学習に電気代がいくらかかるか
ここでは実際にフェルミ推定を行い、GPT-5 の学習に必要な電気代を概算してみましょう。
仮定
| 項目 | 値 | 根拠 |
|---|---|---|
| GPU 数 | 25,000 基 | GPT-4 の10,000基から2.5倍と想定 |
| 学習期間 | 90 日 | 6ヶ月の半分を実学習と想定 |
| GPU あたり消費電力 | 700 W | H100 SXM の TDP |
| PUE | 1.3 | 大規模施設の標準的な値 |
| 電気料金 | $0.05/kWh | 米国データセンター向け卸売価格 |
計算
総消費電力 = 25,000 × 700W × 1.3 (PUE) = 22,750 kW(約 22.75 MW)
学習期間の総電力量 = 22,750 kW × 90日 × 24時間 = 49,140,000 kWh(≈ 49.1 GWh)
電気代 = 49,140,000 kWh × $0.05/kWh = $2,457,000(約 $2.5M ≈ 約3.7億円)検算
この $2.5M という電気代は、GPT-5 の推定総学習コスト $1.7B〜$2.5B の わずか約 0.1% に過ぎません。これは一見少なく見えますが、学習コストの大部分は GPU の償却費(購入 or レンタル)、人件費、施設コスト によるものであり、電気代自体は全体の一部に過ぎないことを意味しています。
GPU レンタル費用で検算すると:
H100 レンタル: $3.00/hr × 25,000基 × 90日 × 24hr = $162Mこれは推定レンジの下限 $1.7B の約 10% にあたり、残りの 90% はGPU以外の研究開発費・人件費・インフラで説明がつきます。
GPU 輸出規制と「脱 NVIDIA」の動き
規制の現状
米国はNVIDIA製の先端AIチップ(H100、H200、B200等)の中国向け輸出に厳格なライセンス要件と性能制限を課しています。2026年初頭には中国側が NVIDIA H200 の輸入を禁止する措置を取り29、NVIDIA は同年Q1に中国向け GPU 供給を 30% 削減 すると発表しました2。
ByteDance、Alibaba、Tencent、DeepSeek といった中国テック大手は H200 の条件付き購入承認を得ましたが、国産チップとのバンドル要件など厳しい制約が付いています30。
GLM5 が示す「脱 NVIDIA」の道
GLM5 は、中国の AI 企業がNVIDIA非依存でフラグシップモデルの学習を実現できることを証明しました1。Huawei Ascend チップと MindSpore フレームワークによる学習は、中国の AI エコシステムの自立化を象徴しています。
ただし、中国のデータセンターにおける AI 学習チップの 75% は依然として CUDA(NVIDIA) を利用しており31、CUDA のソフトウェアエコシステムの再現には数年を要すると見られています。GLM5 のアプローチは重要な一歩ですが、エコシステム全体の転換にはまだ時間がかかるでしょう。
まとめ──コスト構造から見える AI の未来
この記事で明らかになったことをまとめます。
- 学習コストは指数関数的に増加中: 現在の $1B 級から、2027年には $10B 級に達する可能性がある
- 効率化の「抜け道」も存在: DeepSeek V3 は MoE + FP8 で Llama 3 の 1/11 のコストを実現。アーキテクチャの工夫がコスト差を生む
- 電力と冷却が物理的ボトルネック: 世界の DC 電力消費は2026年に 1,050 TWh、冷却は全エネルギーの 30-40% を占める
- GPU 調達に地政学リスク: 輸出規制と供給削減により、中国は国産チップへの移行を加速。GLM5 はその象徴
- 「学習コスト」の定義に注意: 各社の公表値は算出範囲が異なるため、単純比較には慎重さが必要
AI のコスト構造を理解することは、モデルの性能比較だけでは見えない「持続可能性」と「競争力の源泉」を把握する鍵です。
参考文献
Footnotes
Trending Topics EU - GLM5 Release - GLM5 が Huawei Ascend チップで学習された詳細 ↩ ↩2
eteknix - NVIDIA Supply Cut - NVIDIA の中国向け GPU 供給 30% 削減 ↩ ↩2
TIME - AI Training Cost Projections - Dario Amodei CEO のコスト予測発言 ↩
SYZ Group (HSBC Estimate) - GPT-5 学習コスト $1.7B〜$2.5B ↩
Fanatical Futurist - GPT-5 コンピュート費用 $500M 超 ↩
Visual Capitalist - Gemini Ultra 学習コスト $192M ↩
Futurum Group - Google FY2026 AI CAPEX $175B〜$185B ↩
Forward Future AI - Claude 3 学習コスト「数千万ドル」 ↩
Tom’s Hardware - Meta の 130 万 GPU 計画と $115B-$135B CAPEX ↩
Stratechery - DeepSeek V3 の $5.6M 学習コスト分析 ↩
Medium - DeepSeek Analysis - DeepSeek の総 CAPEX $1.6B 分析 ↩
Interconnects.ai - DeepSeek V3 が Llama 3 の 1/11 の GPU 時間で学習 ↩
Medium - 100MW Facility Cost - 100MW AI 施設の年間運営コスト ↩ ↩2 ↩3
Tom’s Hardware - NVL72 - B200/NVL72 の価格情報 ↩
The Network Installers - DC コスト内訳(電力 40-60%、人件費 20-25%) ↩ ↩2
S&P Global - 米国 DC 電力需要 75.8 GW 予測 ↩
Capacity Global - 電気代 5 年で 267% 上昇 ↩
RCR Wireless - 直接液冷市場 2030 年 $8B 超 ↩
Random Lengths News - 水消費 500 万ガロン/日 ↩
Dev Sustainability - PUE ベンチマーク(業界平均 1.58、Google 1.08) ↩
Weighty Thoughts - 中国 DC の 75% が CUDA 利用 ↩