
DeepSeek V4-Pro/Flash がアツい:1.6T MoE を Opus 4.7 の1/6 価格で投げ込んできた中国オープンウェイトの一手
はじめに
2026年4月24日、DeepSeek が V4 Preview を発表してウェイトを同時公開しました1。ラインアップは2本立てで、フラッグシップの V4-Pro が1.6T 総パラメータ/49B アクティブ、軽量側の V4-Flash が284B 総/13B アクティブ。両方とも 1M トークンのコンテキストが標準で、Thinking / Non-Thinking のデュアルモードを備えています12。
数字の異常さがいくつかあります。競技コーディング系(LiveCodeBench、Codeforces、Apex Shortlist)の比較表で V4-Pro-Max が単独首位を取り、SWE-Bench Verified では Claude Opus 4.6 と実質同点(80.6 vs 80.8)まで詰めました2。それでいて API 価格は V4-Pro が GPT-5.5/Opus 4.7 比で約65%安、V4-Flash の出力単価に至っては約99%安($0.28/1M tok vs $30/1M tok)です34。
ただし、最新世代のクローズド(GPT-5.5、Claude Opus 4.7)に対しては HLE や Terminal-Bench 2.0、SWE-Bench Pro で明確に劣後する領域もあり、「全方位フロンティア互角」ではありません4。本記事は、性能・比較・比較優位ユースケースの順で、現実的なポジションを整理します。
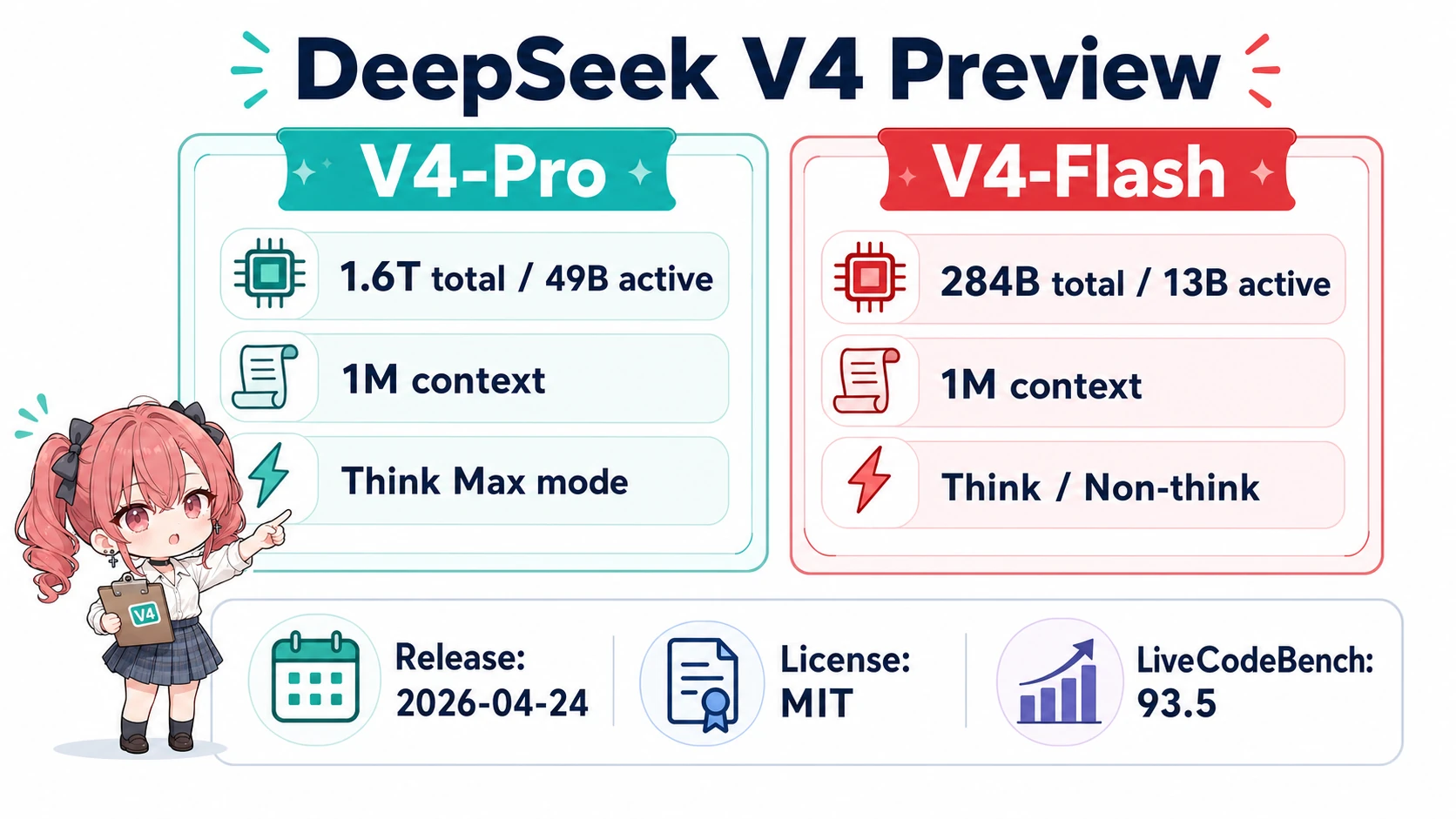
モデル性能:1.6T MoE で競技コーディング世界一、SWE-Bench で Opus 4.6 に並ぶ
まずモデルの基礎仕様を整理します。
| モデル | 総パラメータ | アクティブ | コンテキスト | 推論モード |
|---|---|---|---|---|
| V4-Pro | 1.6T | 49B | 1M | Non-think / Think / Think Max |
| V4-Pro-Max | (V4-Pro の最大努力モード) | 49B | 1M | Think Max のみ |
| V4-Flash | 284B | 13B | 1M | Non-think / Think |
V4-Pro は MoE 構成で、1.6T の知識量を持ちながら 1 トークンあたりの活性化は 49B に抑えています2。Pro と Flash の違いは「Pro=深い推論で品質、Flash=コスト最適で速度」という棲み分けです。
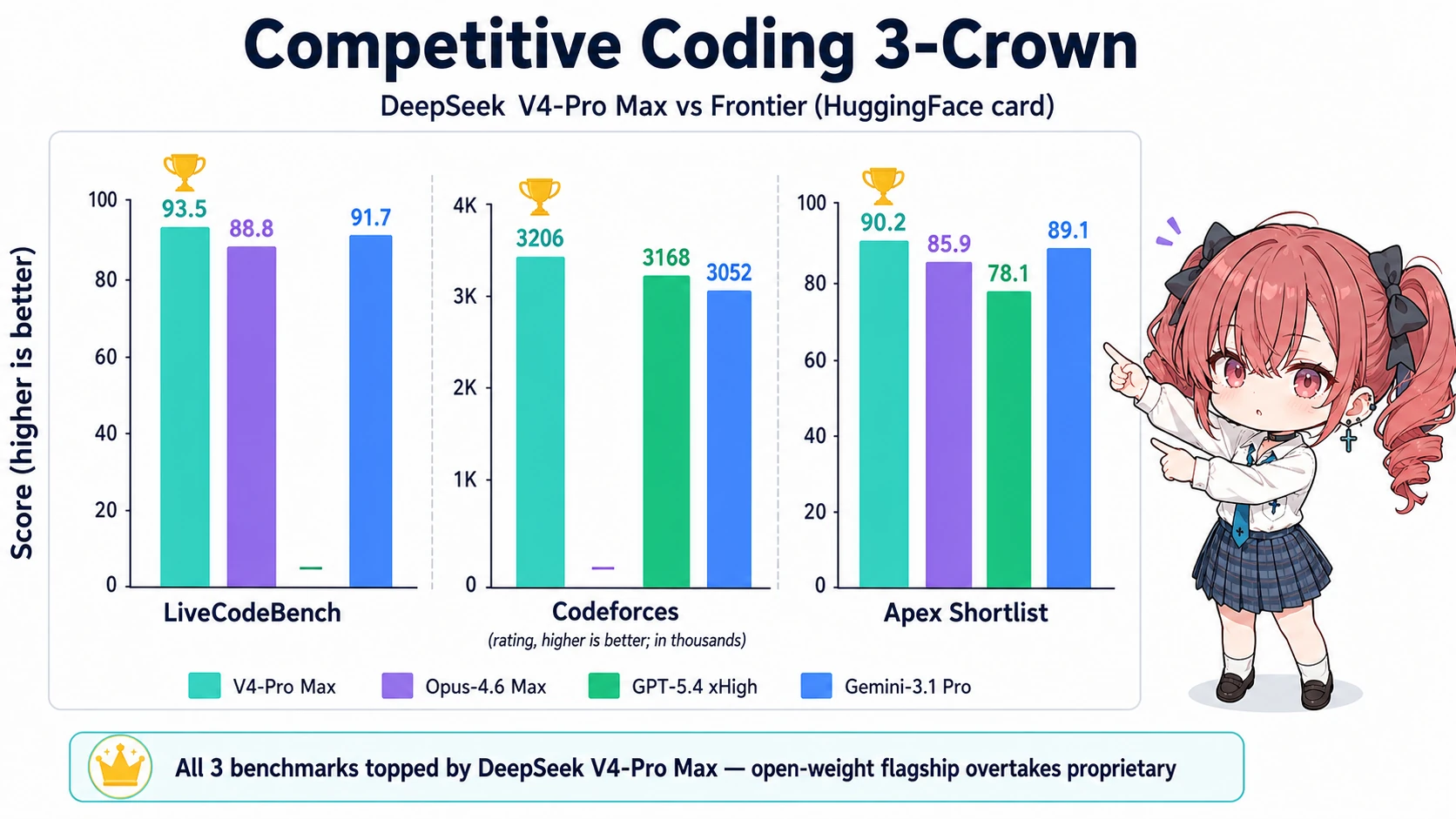
ベンチを見るとアツさが分かります。HuggingFace 公式モデルカード掲載の比較表(V4-Pro-Max vs 旧世代フロンティア)から、コーディング・推論系の主要数値を抜粋します2。
| ベンチマーク | V4-Pro Max | Opus-4.6 Max | GPT-5.4 xHigh | Gemini-3.1-Pro | K2.6 Thinking |
|---|---|---|---|---|---|
| LiveCodeBench | 93.5 | 88.8 | — | 91.7 | 89.6 |
| Codeforces (rating) | 3206 | — | 3168 | 3052 | — |
| Apex Shortlist | 90.2 | 85.9 | 78.1 | 89.1 | 75.5 |
| SWE-Bench Verified | 80.6 | 80.8 | — | 80.6 | 80.2 |
| HMMT 2026 Feb | 95.2 | 96.2 | 97.7 | 94.7 | 92.7 |
| GPQA Diamond | 90.1 | 91.3 | 93.0 | 94.3 | 90.5 |
| MRCR 1M (long ctx) | 83.5 | 92.9 | — | 76.3 | — |
注目どころは3つあります。
- 競技コーディング3冠:LiveCodeBench 93.5、Codeforces レーティング 3206、Apex Shortlist 90.2 はいずれもこの比較表で V4-Pro-Max が単独首位です。Codeforces 3206 は人間トップ層(Grandmaster クラス)の領域で、コード生成側で Gemini 3.1 Pro と GPT-5.4 を抜きました2。
- SWE-Bench Verified が Opus 4.6 と実質同点:80.6 vs 80.8 は誤差レベル。Gemini 3.1 Pro とは完全同点です。実リポジトリの GitHub Issue 解決ベンチで、ついに MIT ライセンスのオープンウェイトが80% 帯に入った形です。
- 長文脈リコールは2位:1M MRCR で Opus 4.6 (92.9) に次ぐ 83.5。Gemini 3.1 Pro の 76.3 を上回り、1M context が「載るだけ」ではなく「リコールできる」ことを示しました。
逆に、純粋な知識量・QA 精度(SimpleQA、HLE、GPQA Diamond)では Gemini 3.1 Pro が圧倒的に強く、V4 はここで差を付けられています。
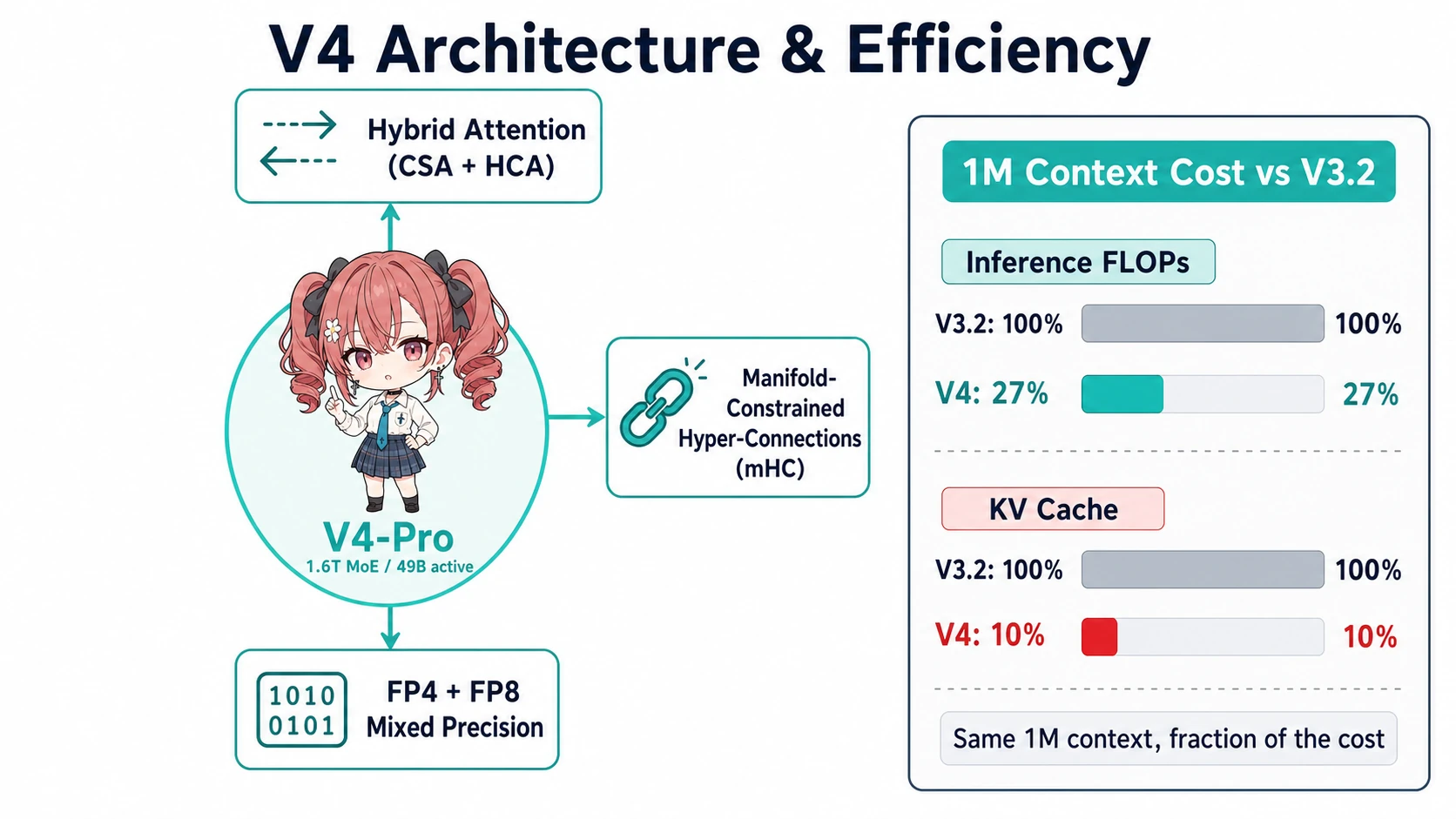
性能の正体:DSA + mHC + 1M コンテキストの経済性
この性能を成立させているのが、DeepSeek が今回投入した3つの構造改良です125。
- Hybrid Attention(CSA + HCA):Compressed Sparse Attention と Heavily Compressed Attention の組み合わせ。公式発表上は “DSA (DeepSeek Sparse Attention)” + Token-wise compression のブランドで一括表記されています。1M context での 推論 FLOPs が V3.2 比 27%、KV キャッシュは 10% まで圧縮5。
- Manifold-Constrained Hyper-Connections (mHC):1.6T MoE のような巨大ネットワークで残差信号を安定伝播させるための仕組み。学習中の勾配不安定を抑え、トリリオン級 MoE が「安定して収束する」ことを可能にしました。
- FP4 + FP8 Mixed Precision:MoE の expert パラメータを FP4、その他を FP8 にする混合精度。32T+ tokens の学習を Muon optimizer で回しつつ、推論時のメモリ帯域も削減5。
ここで効いてくるのが 「1M context が標準で、しかも経済的に成立している」 という事実です。GPT-5.5 / Opus 4.7 も 1M context は提供していますが、フル活用すると1リクエスト数ドル単位になり気軽には使えません。V4-Pro は同じ 1M に対して入力単価 $1.74/1M で、しかも KV キャッシュが 1/10 のため運用側の GPU 帯域も軽い、という二重の有利を取りに来ています。
オープン陣営での位置取り:Qwen3.6-27B / GLM-5.1 / Kimi K2.6 と何が違う
オープンウェイト勢の中で V4 がどこに立つか。直近2か月のリリースと並べると、戦略の方向が真逆であることが分かります。
| モデル | サイズ | 戦略の方向 | 強み |
|---|---|---|---|
| Qwen3.6-27B (4/22) | 27B dense | 圧倒的に小さく寄せる | ローカル実行、Apache 2.0、SWE-Verified 77.2 |
| GLM-5.1 Thinking | (MoE) | 中堅サイズで価格訴求 | コスト効率、SWE-Pro 58.4 |
| Kimi K2.6 Thinking | (MoE) | 推論モードで品質追求 | SWE-Pro 58.6(オープン勢首位) |
| DeepSeek V4-Pro | 1.6T / 49B | 規模の暴力 + 経済性両立 | 競技コーディング3冠、1M context 実用化 |
Qwen3.6-27B は「ローカル GPU でフラッグシップ級が動く」方向に最適化したのに対し、V4-Pro は 「クラウド API 前提だが、規模で押し切ってクローズドに迫る」 という真逆のアプローチです。両者は同じオープンウェイトでも狙う市場が違っていて、開発者は使い分けることになります。
- 24GB GPU や Mac で動かしたい → Qwen3.6-27B
- API で 1M context をフルに使いたい / 規模が必要 → DeepSeek V4-Pro
- SWE-Bench Pro 重視のエージェント → Kimi K2.6 か GLM-5.1
- マルチリンガル + 中国語特化 → V4-Pro(Chinese-SimpleQA 84.4)
V4 が単独で勝った領域は 競技コーディング、長文脈、中国語 QA、価格効率 の4つです。
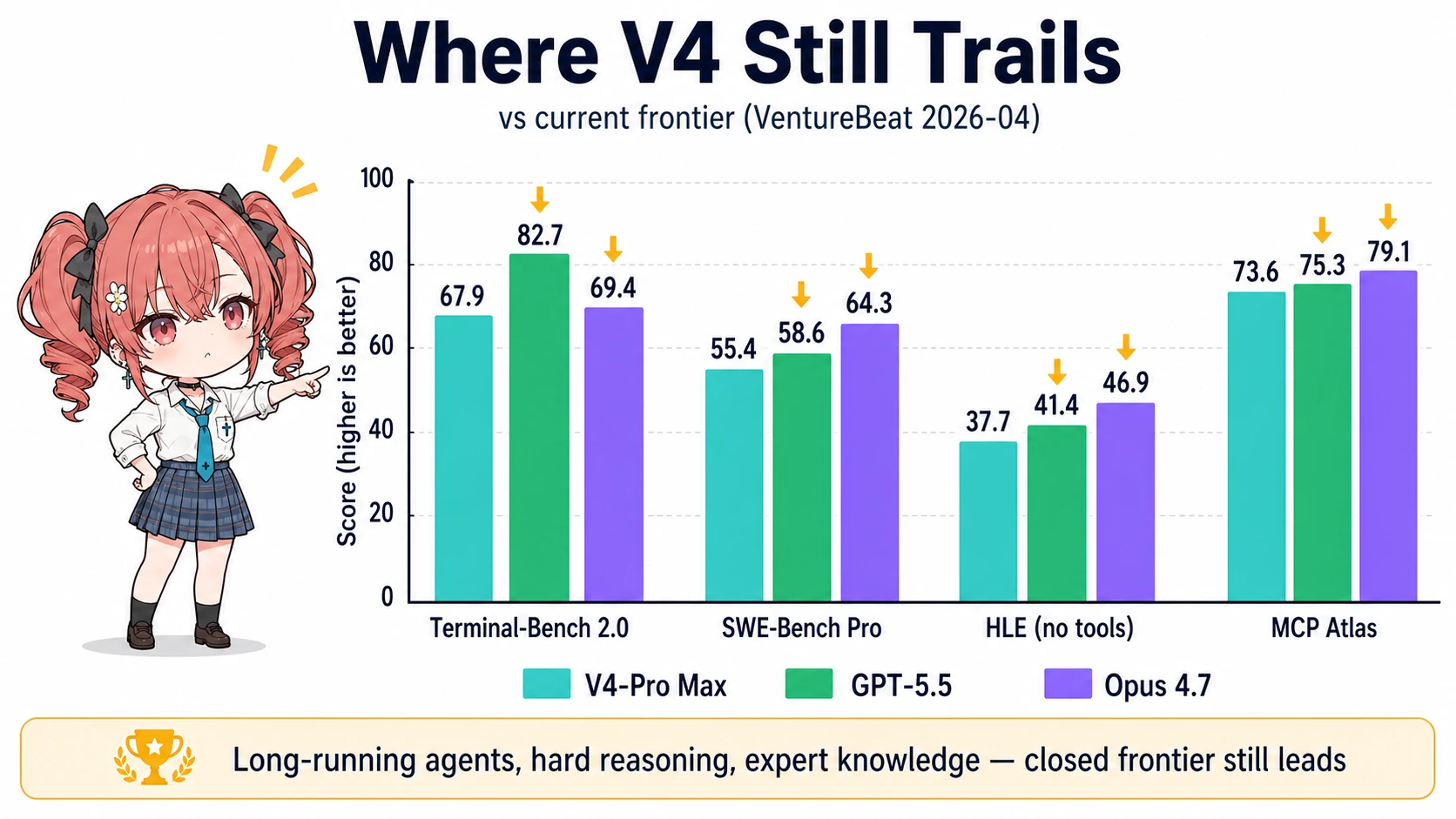
クローズド最新との現実的ギャップ:GPT-5.5 / Opus 4.7 にはまだ届かない領域
ただし、最新世代のクローズドフラッグシップ(GPT-5.5、Claude Opus 4.7、GPT-5.5 Pro)に対しては正直に劣後します。VentureBeat 集計から、現行最新と直接比較した数値です4。
| ベンチマーク | V4-Pro Max | GPT-5.5 | GPT-5.5 Pro | Opus 4.7 |
|---|---|---|---|---|
| Terminal-Bench 2.0 | 67.9 | 82.7 | — | 69.4 |
| SWE-Bench Pro | 55.4 | 58.6 | — | 64.3 |
| MCP Atlas | 73.6 | 75.3 | — | 79.1 |
| HLE (no tools) | 37.7 | 41.4 | 43.1 | 46.9 |
| HLE (with tools) | 48.2 | 52.2 | 57.2 | 54.7 |
| BrowseComp | 83.4 | 84.4 | — | 79.3 |
差が目立つのは Terminal-Bench 2.0(GPT-5.5 が +14.8pt)、SWE-Bench Pro(Opus 4.7 が +8.9pt)、HLE(Opus 4.7 が +9.2pt)の3つです。長期エージェント実行・ハード推論・専門知識の領域では、現行最新のクローズドが頭ひとつ抜けています。
ただし BrowseComp(Web ブラウジング・エージェント)では V4 が Opus 4.7 を上回り、GPT-5.5 とは 1pt 差。長時間ループしないシングルクエリ系のエージェントでは、価格差を考えると V4 を選ぶのが合理的、という構造です。
DeepSeek 自身も「ベンチで全勝した」とは言っておらず、CNBC レポートでは Counterpoint アナリストが 「コスト比で見たエージェント能力に強み」 とコメントしています6。
1/6〜1/100 の価格破壊
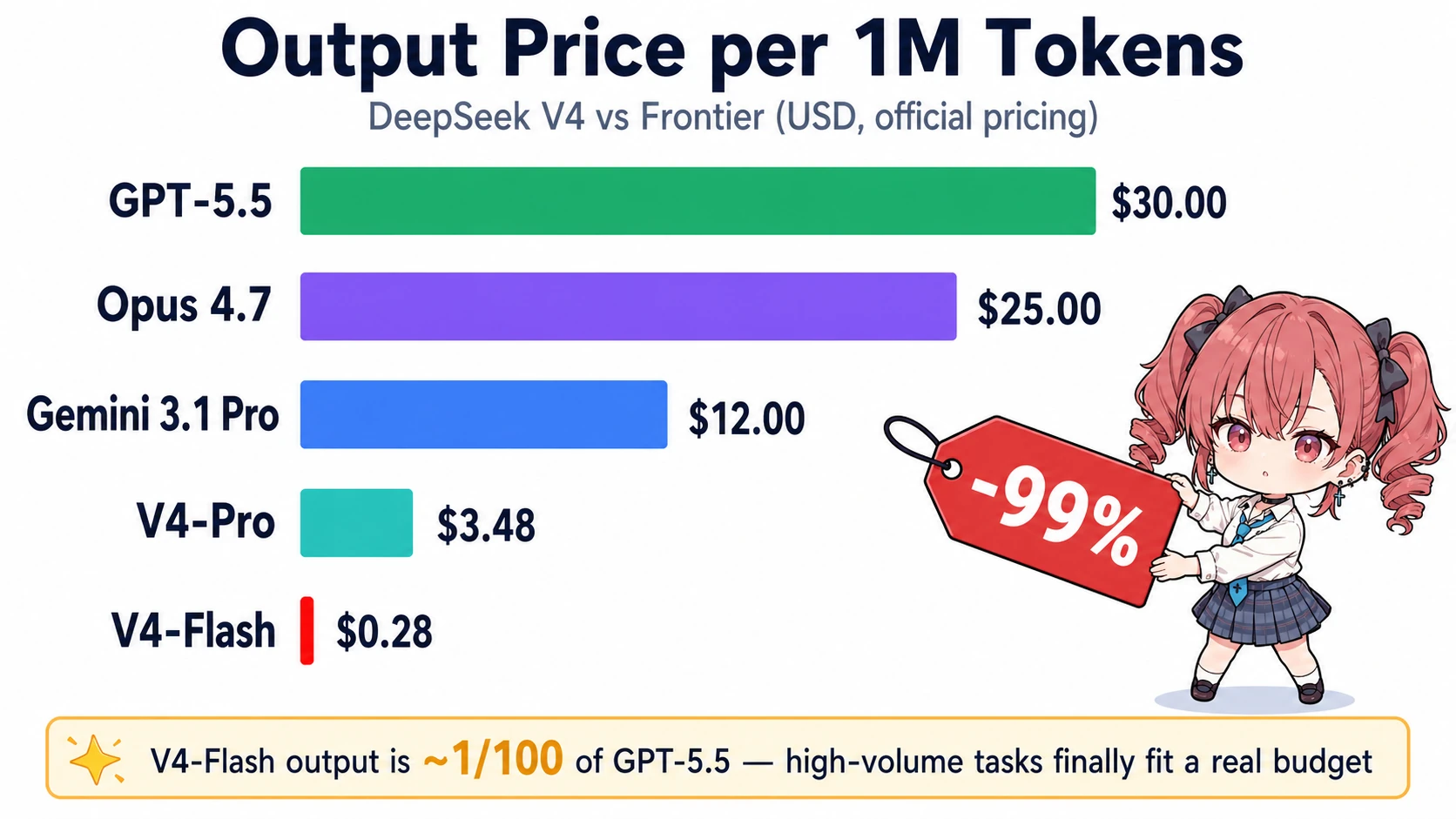
最大の差別化要因は価格です。1M トークン単位で並べます34。
| モデル | Input ($) | Output ($) | コンテキスト |
|---|---|---|---|
| V4-Pro | 1.74 | 3.48 | 1M |
| V4-Flash | 0.14 | 0.28 | 1M |
| GPT-5.5 | 5.00 | 30.00 | 1M |
| Claude Opus 4.7 | 5.00 | 25.00 | 1M |
| Gemini 3.1 Pro | 2.00 | 12.00 | — |
V4-Pro は 入力で65%安、出力で86%安。V4-Flash の出力 $0.28 は GPT-5.5 比で99%以上安く、Mashable 試算では「$5.22 で済む V4 タスクが GPT-5.5 だと $35」というオーダー差になります3。
これが効くのは、以下のような 「品質より試行回数で殴る」 用途です。
- 大量並列の RAG / 文書要約バッチ
- アイデア生成・variant explorations
- 検索エージェントの中間ステップ(最終ステップだけ高品質モデルに投げる)
- 開発時のプロトタイピング・ユニットテスト生成
逆に「失敗が高くつく1ショット推論」(製品コードのリリース判断、医療・金融の意思決定)では、最新クローズドの優位性が価格差を正当化します。
比較優位を活かす3つのユースケース
ここまでの整理を踏まえ、V4 を「アツい」と感じられる具体的な使い方を3つ。
1. agentic コーディングを V4-Pro で常時駆動
Claude Code / OpenClaw / OpenCode は V4 と公式統合されており、API は OpenAI ChatCompletions と Anthropic API の両方互換です1。base_url を https://api.deepseek.com に向けて model を deepseek-v4-pro にするだけで、既存の Cline / Claude Code セットアップが V4 駆動になります。
SWE-Bench Verified 80.6 の品質を出力 $3.48/1M tok で回せる、というのは 「常時バックグラウンドでリポジトリを触らせる」 運用が現実的になったということです。Claude Code を Opus 4.7 で常時動かすと月額コストが跳ねますが、V4-Pro なら同等のループを 1/7 程度のコストで回せます。
2. V4-Flash で1M context の RAG パイプラインを大量バッチ
V4-Flash は出力 $0.28/1M tok で 1M context を提供します。これは 「数千件の長文ドキュメントに同じ質問を投げ続ける」 RAG / 分析バッチで決定打になります。
具体例:
- 法務 / 契約書の差分抽出を全社契約 5000 件にバッチ実行
- 過去5年分の Slack ログから「特定プロジェクトの意思決定経緯」を全部走らせて再構成
- 論文 1000 本に対して「特定手法の実装可否」をフル本文で判定
GPT-5.5 でこれをやると6桁ドル単位、V4-Flash なら3桁〜4桁ドル単位に収まります。
3. MIT ライセンス + ウェイト公開で規制業界のオンプレ展開
V4 は MIT License で重みが公開されています2。商用利用も改変も再配布も自由で、これは規制業界(金融・医療・防衛・政府)にとって決定的に重要です。
クラウド API に投げられない機密データを抱える組織でも、V4-Pro のウェイトを社内 GPU クラスタに展開すれば、Opus 4.6 同等の SWE-Bench スコアを社内データだけで回せます。FP4/FP8 mixed precision なので、H200/B200 8 枚クラスタで 1M context まで現実的に走らせられる構成です。
注意点:手放しで称賛できない部分
ここまでアツさを語ってきましたが、冷静に見るべき点もあります。
Preview ステータス:V4 は “Preview” として公開されており、安定版ではありません1。本番採用前に、自社のスキャフォールドや MCP 統合での再評価が必要です。
最新クローズドとの差:Terminal-Bench 2.0、SWE-Bench Pro、HLE では GPT-5.5 / Opus 4.7 にまだ追いついていません4。「フロンティア互角」とまでは言えず、「near-frontier を1/6 で出してきた」 という表現が正確です。
ベンチ評価の前提:HuggingFace 掲載スコアは DeepSeek 内製の評価環境込みです。第三者の独立再現は2026年4月25日時点で限定的なので、自社ユースケースで触ってみるのが堅実です。
deepseek-chat / deepseek-reasoner の廃止:旧モデルは2026-07-24 15:59 UTC で完全廃止予定1。既存実装は順次マイグレーションが必要です。
まとめ
DeepSeek V4-Pro/Flash のアツいポイントを整理します。
性能のアツさ:
- LiveCodeBench 93.5、Codeforces 3206、Apex Shortlist 90.2 で競技コーディング3冠
- SWE-Bench Verified 80.6 で Opus 4.6 (80.8) と実質同点
- 1M MRCR 83.5 で長文脈リコール2位(Gemini 3.1 Pro を上回る)
経済性のアツさ:
- V4-Pro は GPT-5.5/Opus 4.7 比で出力 86%安
- V4-Flash の出力 $0.28/1M tok は GPT-5.5 比 99%安
- DSA で 1M context 推論 FLOPs が V3.2 比 27%、KV cache 10%
運用のアツさ:
- MIT License でウェイト公開、商用利用・改変自由
- Claude Code / OpenClaw / OpenCode と公式統合
- OpenAI ChatCompletions / Anthropic API 互換、base_url 切り替えのみ
現実的な限界:
- GPT-5.5 / Opus 4.7 に Terminal-Bench / SWE-Bench Pro / HLE で劣後
- Preview ステータス、第三者再現は限定的
- 知識集約 QA は Gemini 3.1 Pro が依然強い
Qwen3.6-27B が「ローカル実行で Opus 級」を出してきた直後に、DeepSeek が「クラウド API で 1.6T 規模を1/6価格」を投げ込んできた格好です。フロンティア性能を求める層(Opus 4.7 / GPT-5.5)と、コスト効率を求める層(V4-Pro/Flash)の二極化が、2026年春のオープン/クローズド構図を決定づけています。週末に deepseek-v4-flash を Cline か Claude Code に挿して、自分のリポジトリで Opus とのコスト/品質曲線を引いてみるのが一番速い理解の仕方です。
参考文献
Footnotes
DeepSeek V4 Preview Release - DeepSeek API Docs ↩ ↩2 ↩3 ↩4 ↩5 ↩6
deepseek-ai/DeepSeek-V4-Pro - Hugging Face ↩ ↩2 ↩3 ↩4 ↩5 ↩6 ↩7
DeepSeek V4: Features, Benchmarks, and Comparisons - DataCamp ↩ ↩2 ↩3
DeepSeek-V4 arrives with near state-of-the-art intelligence at 1/6th the cost of Opus 4.7, GPT-5.5 - VentureBeat ↩ ↩2 ↩3 ↩4 ↩5
China’s DeepSeek releases preview of long-awaited V4 model as AI race intensifies - CNBC ↩