
DiffusionGemma を M5 Pro で実測:拡散LLMの「4倍速」は Apple Silicon で消える
公称「4倍速」を手元の Mac で検証する
2026年6月10日、Google DeepMind が DiffusionGemma を公開しました1。テキストを左から右へ1トークンずつ書く自己回帰生成ではなく、マスクされたトークンの塊(キャンバス)を並列に「ノイズ除去」して一気に確定する、拡散モデル方式の言語モデルです。Apache 2.0 で、25.2B 総パラメータ / 3.8B アクティブの MoE 構成、256K コンテキストに対応します2。
注目を集めたのは速度です。公式は H100 単体で 1,000 tokens/s 超、同等の自己回帰モデルに対して最大 4 倍速いと打ち出しました1。一方で品質は自己回帰版の Gemma 4 を下回る、と明記もしています。つまり「速さと引き換えに質を少し諦めたモデル」という位置づけです。
ここで気になったのが、その「4倍速」は手元の Mac でも本当に出るのか、という点です。公称値は NVIDIA の H100 という演算リッチな環境での数字で、最適化(NVFP4 量子化など)も NVIDIA 向けです。Apple Silicon は事情が違います。そこで、DiffusionGemma と同じ 26B-A4B 基盤の自己回帰モデル Gemma 4 26B-A4B2 を、同じマシン・同じ量子化・同じプロンプトで並べて測りました。生成パラダイムだけを入れ替えた対照実験です。
結論を先に書きます。今の Mac では、拡散版は自己回帰版より遅い。 そして拡散版を自己回帰版の速度に近づけようとすると、その瞬間にコードはコンパイルできなくなり、文章は同じ単語を繰り返し始めます。
何を、どう測ったか
検証環境は手元の MacBook Pro(Apple M5 Pro、ユニファイドメモリ 48GB)です。推論には Apple Silicon 向けの MLX 実装である mlx-vlm 0.6.3 を使い、両モデルとも mlx-community が配布する 4bit 量子化版を使いました3。
- 拡散:
mlx-community/diffusiongemma-26B-A4B-it-4bit(ディスク 16.5GB、ロード後ピーク約 19.4GB) - 自己回帰:
mlx-community/gemma-4-26b-a4b-it-4bit(ピーク約 15.7GB)
測定は temperature=0(貪欲法)で決定論的に揃え、速度は同一プロンプトを 3 回実行した中央値を採りました。コーディング品質は生成コードを bun test の隠しテストで合否判定し、文章品質は英文の distinct-2(重複しない 2-gram 比率)と最頻 4-gram の反復回数で測りつつ、日本語は語境界が空白で取れずメトリクスが当てにならないため本文を目視しました。
計測中に一度、ベンチ末尾の設定でスループットが極端に落ちる値が出ましたが、クールダウンを挟んで単独再計測すると再現しませんでした。サーマルスロットリングの影響と判断し、その値は集計から除いています。以下の数字はすべて、熱の影響が乗っていないことを確認した区間のものです。
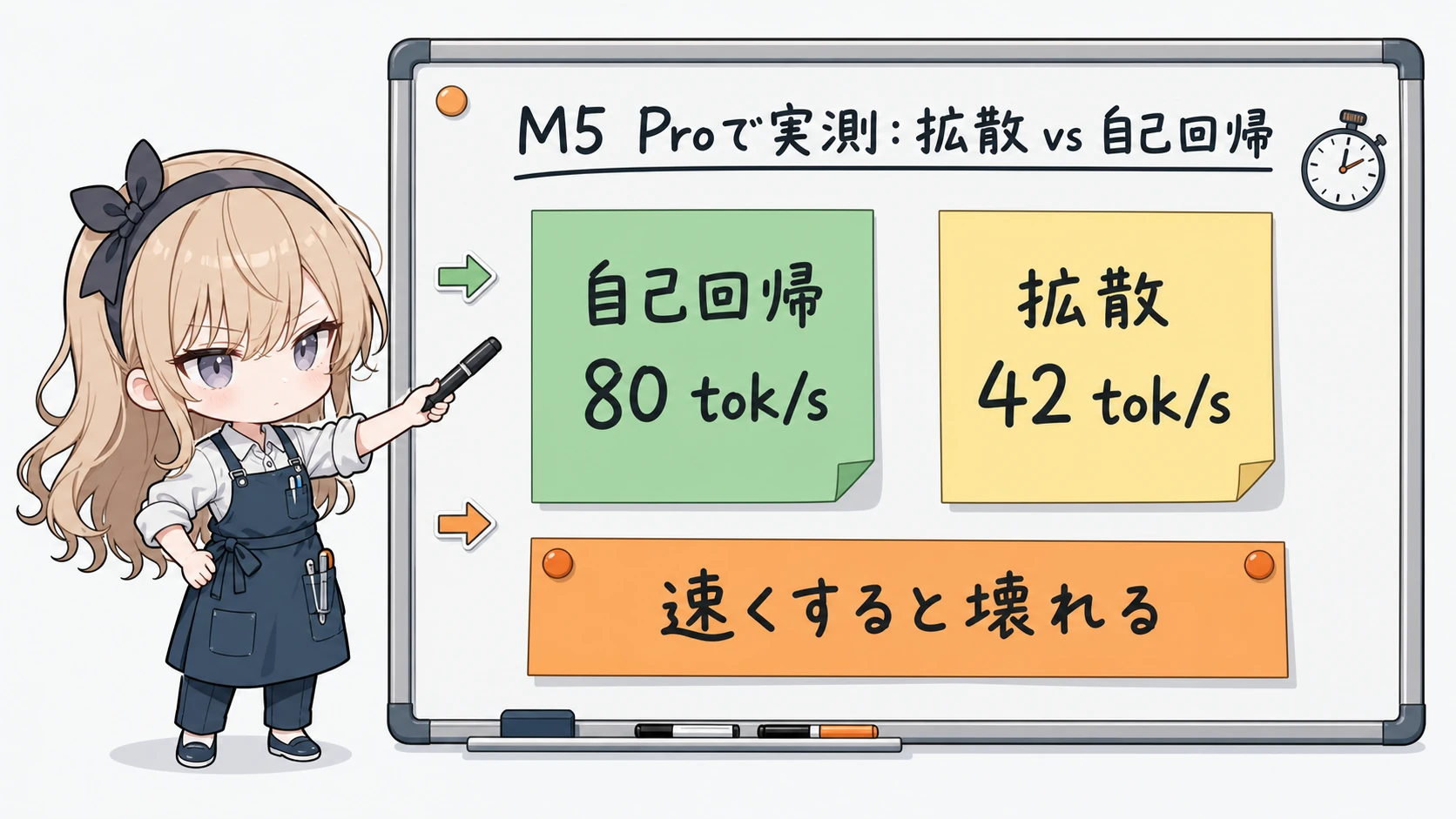
Mac では拡散のほうが遅い
短い質問応答(生成上限 256 トークン)での生成速度です。
| 構成 | 生成 tok/s | 実 denoise ステップ | ピークメモリ |
|---|---|---|---|
| 自己回帰 Gemma 4(baseline) | 80.8 | — | 15.7GB |
| DiffusionGemma(既定) | 42〜47 | 12〜16 | 19.4GB |
| DiffusionGemma(steps=16) | 63.1 | 10 | 19.4GB |
| DiffusionGemma(steps=8) | 70.6 | 8 | 19.4GB |
自己回帰版が 80.8 tok/s で生成するのに対し、DiffusionGemma は既定設定で 42〜47 tok/s。同じパラメータ数・同じマシンで、自己回帰版のほうがおよそ 1.7〜2 倍速い という、公称とは逆向きの結果になりました。公称の「4倍速」どころか、拡散側が負けています。
理由は、拡散が「1トークンを出すために何度もキャンバス全体を計算し直す」点にあります。今回のランでは、確定した出力 1 トークンあたり 17〜32 トークン分の前向き計算が走っていました。H100 のように演算に余裕がある環境では、この余分な計算はほぼ「タダ」で並列処理され、見かけのスループットが伸びます。しかし Mac の推論はメモリ帯域がボトルネックです。並列に計算したい塊が大きいほど帯域を食い、余分な計算がそのまま待ち時間に変わります。拡散が H100 で輝く理由(演算律速)が、Mac ではそのまま不利(帯域律速)に反転するわけです。ピークメモリも、キャンバスと自己条件付けの中間表現を抱える分、拡散版が約 4GB 多く使っていました。
ステップ上限を上げても速くならない
DiffusionGemma の既定サンプラー(entropy-bound)は、キャンバスが十分に収束すると上限に達する前に打ち切る適応停止を持っています。実際、max-denoising-steps を 32 に設定しても 48 に設定しても、実際に回ったステップ数は 12〜16 で頭打ちでした。速度もこの区間ではほぼ横ばいです。
裏を返すと、速度を上げる唯一のレバーは適応停止より下、つまり上限を 8 まで削ることです。steps=8 にすると 70.6 tok/s まで上がり、自己回帰版の 80.8 tok/s に肉薄します。問題は、その速さに何が伴うかです。
速くするとコードが壊れる
3 つのコーディング課題(debounce / 非同期 retry / 期間文字列パース)を生成させ、bun test で合否を取りました。
| 構成 | debounce | retry | parse_duration |
|---|---|---|---|
| 自己回帰 Gemma 4 | 合格 | 合格 | 5/7 |
| Diffusion(steps=16) | 合格 | 合格 | 5/7 |
| Diffusion(steps=48) | 合格 | 合格 | 5/7 |
| Diffusion(steps=8) | 0/1(コンパイル不能) | 合格 | 0/1(コンパイル不能) |
| Diffusion(confidence サンプラー) | 合格 | 0/1(コンパイル不能) | 5/7 |
読み解くと、傾向がはっきり出ています。
既定〜中ステップの拡散(steps=16, 48)は、自己回帰版とまったく同じ成績でした。debounce と retry は両者とも通過し、parse_duration は両者とも同じ 2 件を落とします。落とした 2 件はいずれも ms(ミリ秒)を「分+秒」と誤認するもので、正規表現の単位順序という設計上の罠に全員が等しくはまっていました。つまり、じっくり回した拡散はロジックの正しさという点では自己回帰と互角で、差が出るのは速度だけでした。
ところが、速度を稼ぐ設定に振った瞬間に質が崩れます。steps=8 の生成物はテストの合否以前にそもそもコンパイルが通りません。期間パーサには let totalString = = 0 という = が二重になった行が現れ、debounce のアロー関数も構文が壊れていました。速度を優先する confidence サンプラーでも、retry の関数宣言から function が抜け落ちて署名が壊れていました。
これは自己回帰生成ではまず起きない壊れ方です。左から右へ生成するモデルは、各トークンを直前までの確定列に条件付けるため、= = のような局所的に矛盾した並びを出しにくい。一方、拡散は塊を並列に確定するので、ノイズ除去の回数を削ると「個々には尤もらしいが隣と噛み合わないトークン」をそのまま固定してしまいます。
文章でも同じ壊れ方が出る
英文エッセイ(生成上限 400 トークン)でも傾向は一致しました。
| 構成 | distinct-2 | 最頻4-gramの反復 | 生成 tok/s |
|---|---|---|---|
| 自己回帰 Gemma 4 | 0.975 | 1 | 80.6 |
| Diffusion(steps=48) | 0.974 | 1 | 60.0 |
| Diffusion(steps=16) | 0.969 | 1 | 64.1 |
| Diffusion(steps=8) | 0.743 | 30 | 122.7 |
steps=48・16 では distinct-2 が 0.97 前後で、自己回帰版とほぼ同等のなめらかな文章です。ところが steps=8 では distinct-2 が 0.74 まで落ち、ある 4-gram が 30 回も繰り返されました。実際の出力は途中まで筋が通っていて、後半でこう崩れます。
…we stop stop from reacting reacting to the environment … the the the the the the the the the the…
日本語はメトリクスが当てにならないので本文を読みました。自己回帰版の随筆は破綻がありません。拡散版は steps=48 でも概ね自然ですが、よく見ると読点が 、、 と重なったり、「忍耐を深めて」が「忍耐を深えて」と送り仮名が崩れる箇所が出ます。コードで見た「隣と噛み合わないトークンを確定する」現象が、日本語では送り仮名や句読点の微細な破損として表面化していました。
なぜ Mac で逆転するのか
整理すると、DiffusionGemma の速度優位は前提条件に強く依存しています。
拡散の売りは「1ステップで多数のトークンを並列に進められる」ことです。これは演算ユニットが余っている H100 のような環境で効きます。並列に流せる計算が多いほど、遊んでいた演算資源が埋まり、実効スループットが上がるからです。さらに公称値を支える NVFP4 などの最適化は NVIDIA 専用で、Apple Silicon には乗りません。
Mac の推論は逆に、メモリ帯域で頭打ちになります。ここでは「1トークンあたり 17〜32 トークン分」という拡散の余分な計算が、そのまま帯域の浪費=待ち時間になります。並列性はメリットではなくコストに転じます。自己回帰生成は1トークンあたりの計算が素直に1回分で、しかも逐次的に直前を条件付けるため、速度でも整合性でも Mac に向いていました。
Mac でローカル生成するなら自己回帰が無難
DiffusionGemma は技術として面白いモデルですが、今の Apple Silicon でローカル実行する速度上の理由は見当たりませんでした。
- 既定設定では、同じ A4B 基盤の自己回帰版 Gemma 4 のほうが M5 Pro でおよそ 2 倍速い。公称の「4倍速」は H100 の演算律速を前提にした数字で、帯域律速の Mac では逆転する。
- 適応停止のため、ステップ上限を上げても速くはならない。速度を稼げる唯一のレバー(ステップを 8 まで削る、または confidence サンプラー)は、コードのコンパイル不能・文章の反復崩壊を直接引き起こす。
- じっくり回した拡散は、ロジックの正しさでは自己回帰と互角。ただし速度で負け、メモリも約 4GB 余分に使う。
ローカルでコードや文章を生成したいなら、Mac では引き続き自己回帰モデル(Gemma 4 や Qwen3.6-27B のような dense モデル)が素直な選択です。これは拡散方式そのものの否定ではありません。MLX 側に NVFP4 相当の最適化や、帯域効率の良いキャンバス処理が入れば、結論は変わり得ます。そのときはまた同じ土俵で測り直すつもりです。
計測条件:Apple M5 Pro / 48GB、mlx-vlm 0.6.3、両モデルとも mlx-community の 4bit 量子化版、temperature=0、速度は3回中央値。コード品質は bun test、文章は distinct-n と反復率+目視。
Footnotes
Google, “DiffusionGemma: 4x faster text generation”(公式ブログ、2026年6月10日). https://blog.google/innovation-and-ai/technology/developers-tools/diffusion-gemma-faster-text-generation/ ↩ ↩2
モデルカード(パラメータ構成 25.2B/3.8B・MoE・256K コンテキスト・Apache 2.0、および自己回帰版 Gemma 4 26B-A4B の対応関係). https://huggingface.co/google/diffusiongemma-26B-A4B-it ↩ ↩2
MLX 4bit 量子化版モデルカード(mlx-vlm 0.6.3 による変換、実行コマンド). https://huggingface.co/mlx-community/diffusiongemma-26B-A4B-it-4bit ↩