
GPT-5.5・Opus 4.7・Gemini 3.1 Pro・Grok 4.3+Mythos:「最強モデル」を捨てオーケストレーションで勝つ
はじめに:2026年4月、5つの駒が揃った
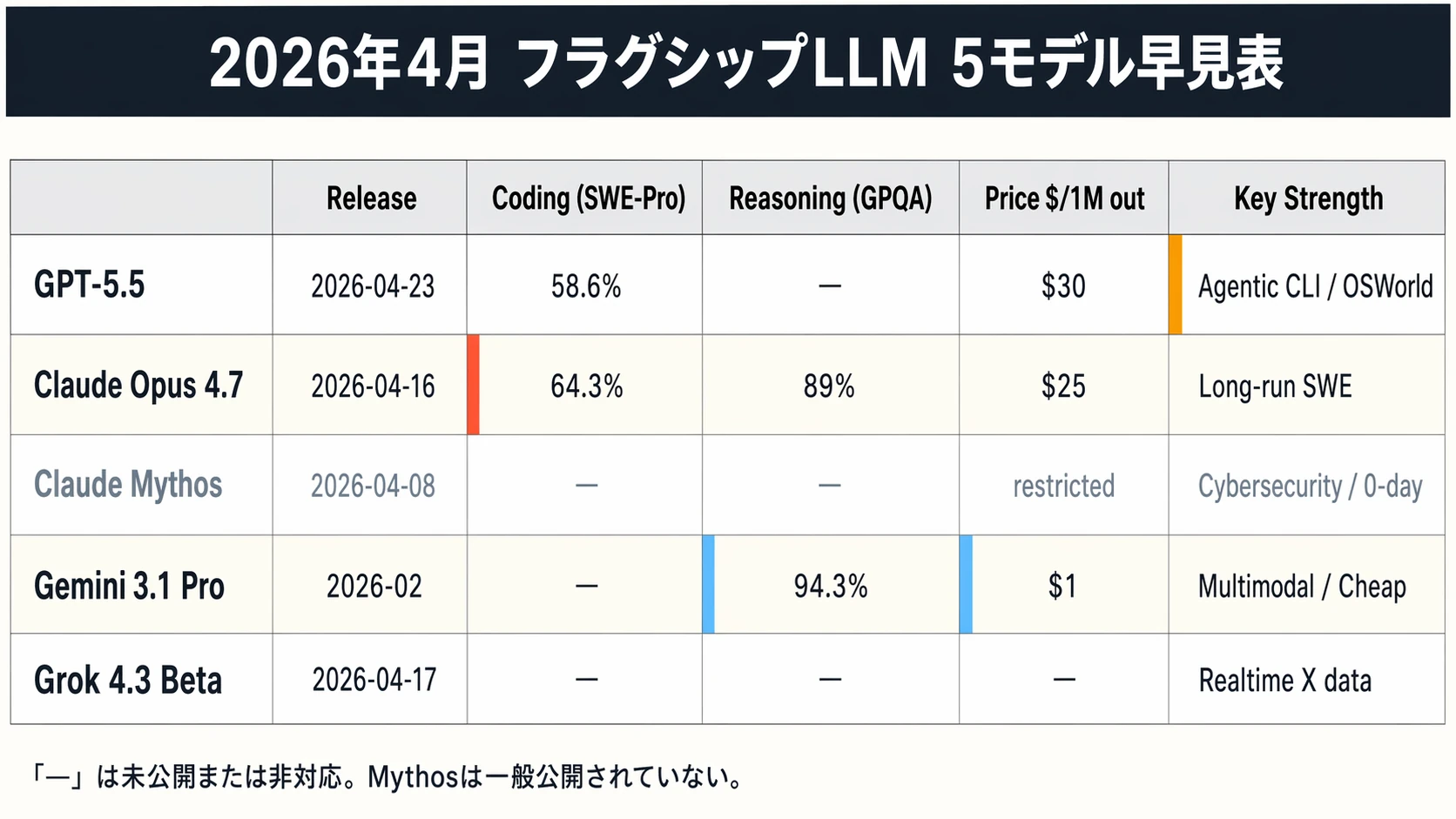
ほんの3週間のあいだに、フラグシップLLMの勢力図が丸ごと描き直された。
- 4月8日:Anthropic が「Capybara」ティアの新モデル Claude Mythos Preview を発表1
- 4月16日:Claude Opus 4.7 が SWE-Bench Pro 64.3% を掲げて登場2
- 4月17日:xAI Grok 4.3 Beta がネイティブ動画理解と Xライブデータを携えて静かに公開3
- 4月23日:OpenAI GPT-5.5 — GPT-4.5 以来初の完全再訓練ベースモデルが登板4
- (2月):Google Gemini 3.1 Pro が GPQA Diamond 94.3% と $0.25/1M の価格で定着5
5つ並んだ駒を見て気づくのは、「万能最強モデル」が意味を失ったことである。SWE-Bench Pro では Opus 4.7 が、Terminal-Bench 2.0 では GPT-5.5 が、GPQA では Gemini 3.1 Pro が、それぞれ頂点を取っている245。勝者がベンチマークごとに入れ替わる時代には、ひとつのモデルを選ぶ発想そのものが最適解から外れていく。
本記事では、5つのモデルを「キャラクター」として理解し直したうえで、複数モデルを組み合わせて使い分けるオーケストレーション設計パターンを4つ提示する。単一最強を追うのをやめ、ポートフォリオとしてAIスタックを組み立てる視点を持ち帰ってほしい。
5つのモデルを「何屋さんか」で理解する
ベンチマーク表を並べて勝敗を採点するのは、この時点で情報量が足りない。各モデルは得意分野と弱点のセットで特徴づけたほうが意思決定に直結する。
GPT-5.5:再訓練された全方位エージェント
GPT-5.5 は GPT-4.5 以来初のフルリトレーンで、OpenAI は「エージェント型コーディングと科学研究の強化」を前面に出している4。
| 指標 | スコア | 備考 |
|---|---|---|
| Terminal-Bench 2.0 | 82.7% | SOTA、コマンドライン長期計画タスク |
| GDPval(44職種業務) | 84.9% | 知識労働生成物の品質 |
| OSWorld-Verified | 78.7% | GUI操作エージェント |
| SWE-Bench Pro | 58.6% | Opus 4.7 より 5.7pt 低い |
| 独立評価ハルシネーション率 | 約86% | Opus 4.7 の約2.4倍6 |
Terminal-Bench 2.0 の 82.7% は突出している7。これは複数ステップにわたるツール連携とプランニングを評価する指標で、実運用のエージェントに近い。ただし陰の数字もある。第三者評価でのハルシネーション率が 86% と報告されており、これは Opus 4.7(36%)の 2倍以上だ6。広く使えるが、事実検証を要する場面では裏取りが必須というキャラクターになる。
価格は $5 input / $30 output per 1M tokens4。Opus 4.7 と同じ入力単価ながら出力は 20% 高い。
Claude Opus 4.7:長距離ソフトウェアエンジニア
Opus 4.7 の SWE-Bench Pro 64.3% は、現行の公開モデルで最高値だ2。SWE-Bench Verified は 87.6%、CursorBench は 70%、Terminal Bench 2.0 は 67%。ベンチのブレ幅が示唆するのは、複数ファイルにまたがる長期タスクでの自己検証能力が際立つという特性である8。
2026-04-16 のリリースでは、新しい xhigh 努力レベル(high と max の中間)が追加された9。Claude Code のデフォルトも xhigh に移り、「high では質が足りず max では遅すぎる」という典型的なコーディング要求にターゲティングされている。
ハルシネーション率は 36% と、主要モデルの中で最も低い6。持久戦と検証に強い。
価格は $5 / $25、コンテキスト 1M2。
Claude Mythos Preview:『禁じられた』専門家
フラグシップ論争に影を差すのが、Anthropic が「Capybara」ティアと呼ぶ新階層の Claude Mythos Preview だ1。Opus の上に位置づけられる階層で、Opus 4.6 比で coding・academic reasoning・cybersecurity のスコアが「劇的に向上」したとされる10。
内部テストで、主要なOS・Webブラウザすべてにおいて自律的に 0-day 脆弱性を発見・悪用したと報告されている(OpenBSD の 27年物のバグ、FFmpeg H.264 の 16年物の脆弱性を含む)11。
ただし一般公開されない。Anthropic は「Project Glasswing」と呼ぶ選定企業コンソーシアムへの限定開放を選んだ12。つまり Mythos はアクセス設計そのものがメッセージになっている——「フロンティアモデルは、もはやAPIで誰でも買えるものではない」と宣言する存在である。この事実は後述のオーケストレーション設計にも跳ね返ってくる。
Gemini 3.1 Pro:安さと知識とマルチモーダルの巨人
Gemini 3.1 Pro の立ち位置は、価格と知識タスクの両方で一段ズレている。
- GPQA Diamond 94.3%(最高)5
- SimpleQA-Verified で競合をリード5
- ネイティブ入力:テキスト/コード/画像/音声/動画/PDF
- 価格:$0.25 input / $1.00 output per 1M tokens(音声は $0.50/$1.50)13
- Context caching 適用で $0.05/1M まで落ちる13
Opus 4.7 や GPT-5.5 との価格差は20倍である。「高品質が必要ない入口の捌き」や「大量の事前フィルタリング」を Gemini に任せ、重いタスクだけ上位モデルに送る、という構成が経済合理性を持つ。音声/動画入力ネイティブという点は、他モデルには簡単に真似できない構造的アドバンテージだ。
Grok 4.3 Beta:リアルタイム監視員
Grok 4.3 Beta は、X プラットフォームのリアルタイムデータへのネイティブアクセスと、4.3 で新たに加わった動画理解が中核の差別化要素だ3。標準ベンチマーク(SWE-Bench, GPQA など)のスコアはほとんど公開されていないため、汎用能力を他モデルと横並びで測ることはできない。
意味があるのは「他モデルにできないこと」だけである——X 上で今まさに起きている会話・トレンド・速報に触れる用途では、代替は存在しない。
ベンチマーク読解:勝者が入れ替わる構造
5つのモデルが「どこで勝つか」が違うことは、もう見てきた通りだ。問題は、その構造を理解しないまま単一指標で選ぶと、実ワークロードと乖離することにある。
同じ「コーディング」でも指標で勝者が違う
| ベンチマーク | 評価対象 | 勝者 | スコア |
|---|---|---|---|
| SWE-Bench Pro | 複数ファイル・難 GitHub issue 解決 | Opus 4.7 | 64.3% |
| SWE-Bench Verified | 単一パッチ型の issue 解決 | Opus 4.7 | 87.6% |
| Terminal-Bench 2.0 | コマンドライン計画+ツール連携 | GPT-5.5 | 82.7% |
| OSWorld-Verified | GUI 操作(マウス・キーボード) | GPT-5.5 | 78.7% |
| CursorBench | IDE 統合下での実作業 | Opus 4.7 | 70% |
「コーディングで強いモデルはどれか」という問いはもう成立しない。複数ファイルのリファクタを任せるなら Opus 4.7、CLI で走らせるエージェントを組むなら GPT-5.5、GUI を叩かせるなら GPT-5.5、……というように、タスク形状に合わせて別モデルが最適解になる。
規模≠信頼性:ハルシネーションの非対称性
もうひとつ見落とせないのが、第三者評価でのハルシネーション率である。GPT-5.5 が 86%、Opus 4.7 が 36% という報告は、規模・新しさ・再訓練が事実性を自動保証しないことの証左である6。
これが後述する Verifier Pattern の理論的背景になる。片方で生成し、片方で検証する——ただし、どちらを「生成役」にしてどちらを「検証役」にするかで出力の質が変わる。ハルシネーション非対称性はオーケストレーションの設計変数である。
オーケストレーション設計パターン4つ
ここから先が記事の主題だ。単一モデルを選ぶのではなく、複数モデルをどう組み合わせるかを4つのパターンに分けて整理する。
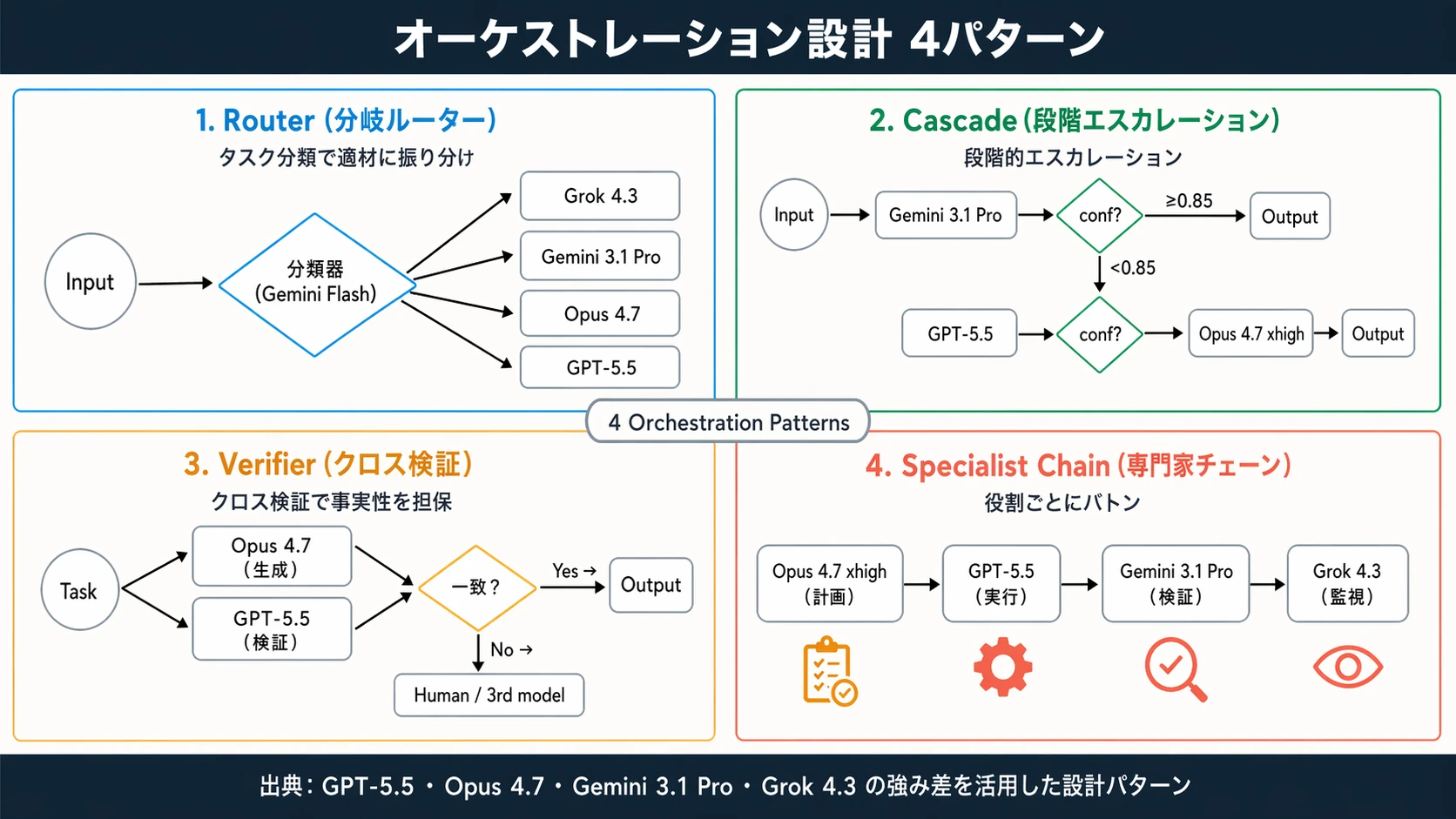
Pattern 1:Router(分岐ルーター)
最もシンプルで、最も効果の大きいパターン。入力を分類し、タスク種別に応じて適切なモデルへ振り分ける。
# 疑似的なルーティング定義routes: - match: { intent: realtime_social } model: grok-4.3 reason: X ライブデータが必須 - match: { intent: factual_qa, complexity: low } model: gemini-3.1-pro reason: GPQA 最強・価格1/20 - match: { intent: code_multifile_refactor } model: claude-opus-4.7 effort: xhigh reason: SWE-Bench Pro 最強 - match: { intent: agentic_cli_task } model: gpt-5.5 reason: Terminal-Bench 2.0 SOTA - default: model: gemini-3.1-pro reason: 不明ならまず安価に流すポイントは分類器自体を安価モデルに担わせることだ。Gemini 3.1 Flash 系や軽量分類モデルで入力意図を推定すれば、ルーターのオーバーヘッドはミリ秒・サブセント単位に収まる。
落とし穴:分類粒度が粗いと誤ルートで品質が崩れる。ログで誤分類を蓄積し、ラベルを増やし続ける運用前提で設計する。
Pattern 2:Cascade(段階的エスカレーション)
まず安価モデルに投げ、信頼度が低ければ上位モデルへ昇格させる。
[入力] → Gemini 3.1 Pro │ ├─ confidence ≥ 0.85 → [出力] │ └─ confidence < 0.85 → GPT-5.5 Thinking │ ├─ confidence ≥ 0.90 → [出力] │ └─ 失敗 → Opus 4.7 xhigh → [出力]信頼度の測り方は 3 系統ある。
- モデル自己申告の confidence:プロンプトで「確信度を 0-1 で出せ」と指示
- Self-consistency:同一プロンプトを温度高で n 回走らせ、回答一致率を使う
- 外部検証:ユニットテスト、数値検算、スキーマ検証など検証可能な信号を使う
理論上の有効コスト計算は次のようになる。仮にタスクの 60% が Gemini で十分と判定、30% が GPT-5.5 で完了、10% が Opus 4.7 まで行くとする。出力 1K トークン想定で概算すると:
- Gemini 3.1 Pro(60%):0.60 × $0.001 ≒ $0.0006
- GPT-5.5(30%):0.30 × $0.030 ≒ $0.009
- Opus 4.7(10%):0.10 × $0.025 ≒ $0.0025
- 合計有効コスト:約 $0.012 / タスク
同じタスクをすべて Opus 4.7 で走らせると $0.025 / タスクなので、約50%のコスト削減が見込める。ただし Cascade は遅延の直列加算が発生する。リアルタイム要件の厳しいタスクには不向きだ。
Pattern 3:Verifier(クロス検証)
同じタスクを 2つ以上のモデルで実行し、差分を検知する。重要な生成物(コード、医療情報、金融計算、法律文書)で有効である。
[タスク] ─┬→ Opus 4.7(生成者)→ [出力A] │ ↓ └→ GPT-5.5(検証者)→ [出力A の監査レポート] │ 一致: [出力A を採用] 不一致: [両者をユーザに提示 or 第3モデル仲裁]ハルシネーション非対称性(GPT-5.5: 86% vs Opus 4.7: 36%)を逆手に取ると、Opus 4.7 を生成者、GPT-5.5 を多様な角度からの批判者に据える構成が合理的になる。異なる学習分布のモデルは、同じ誤りに到達しにくい——独立性が検証の力になる。
コスト倍増のペナルティがあるため、タスクの 5-10% を Verifier にかけるという運用が現実的だ。Pattern 2 の「confidence < 閾値」の判定を Verifier で置き換える合成形もある。
Pattern 4:Specialist Chain(専門家チェーン)
複雑なワークフローを役割ごとに別モデルへバトンする。
[要求] → Opus 4.7 xhigh(長距離プランナー) ↓ 計画書(.md) GPT-5.5(CLI エージェント / Terminal-Bench 強い) ↓ 実装済みコード+テスト結果 Gemini 3.1 Pro(多言語・図表読み・安価検証) ↓ 最終レビューレポート Grok 4.3(X 上の反応・同時発生するニュース監視) ↓ リリース時のコンテキスト注釈 [最終成果物]このパターンの狙いは、各モデルの最強指標を連結することだ。Opus 4.7 は SWE-Bench Pro が強い=計画と設計に向く。GPT-5.5 は Terminal-Bench と OSWorld が強い=手を動かす実行フェーズに向く。Gemini 3.1 Pro は GPQA・マルチモーダル・安価=視覚資料と広い知識レビューに向く。Grok 4.3 はリアルタイム監視=運用や広報のコンテキスト注釈に向く。
注意点はバトン部分のプロトコル設計だ。前段の出力が後段の入力仕様を満たさないと、チェーンは簡単に壊れる。Markdown、JSON Schema、MCP(Model Context Protocol)など構造化された中間表現を前提にする。
ユースケース → パターン対応表
現場のユースケースに 4 パターンをマッピングすると次のようになる。
| ユースケース | 主軸パターン | 理由 |
|---|---|---|
| 企業コーディングエージェント | Specialist Chain | 計画=Opus / 実行=GPT-5.5 / レビュー=Gemini の分業が効く |
| 大量ドキュメントQA | Cascade | 多数はGeminiで捌き、難問だけ上位へ |
| ニュース・速報レポート | Router + Grok | リアルタイム判定に入ったら Grok、それ以外は別モデルへ |
| 金融・医療・法律の文書生成 | Verifier | 生成:Opus 4.7 / 検証:GPT-5.5 のダブルチェック |
| 研究開発リサーチ | Specialist + Verifier | 計画→実行→クロス検証 |
| カスタマーサポート bot | Router → Cascade | インテント分類後、費用を段階的にエスカレーション |
| 画像・動画解析が必要な業務 | Router | マルチモーダル入力は Gemini 3.1 Pro 一択 |
単発タスクなら Router、品質保証が重いなら Verifier、コスト制約がきついなら Cascade、複雑な長距離ワークフローなら Specialist Chain——というタスク形状による選択が設計の出発点になる。
コスト設計:「有効コスト」で考える
単価比較は入口に過ぎない。実務で効いてくるのは 有効コスト(effective cost) である。これは「API 単価 × 使用量」ではなく、「出力品質を満たす最小コスト」のことだ。
単価と有効コストのズレ
| モデル | 入力単価 | 出力単価 | 割引策 |
|---|---|---|---|
| Gemini 3.1 Pro | $0.25 | $1.00 | Context caching で $0.05/1M |
| GPT-5.5 | $5.00 | $30.00 | Batch API で 50% 割引 |
| Claude Opus 4.7 | $5.00 | $25.00 | Prompt caching で最大 90% 節約 |
| Grok 4.3 Beta | 未公開 | 未公開 | — |
Opus 4.7 の Prompt Caching を活用すると、同一システムプロンプトを繰り返し使うユースケースでは実効コストが $0.50/$2.50 まで落ちる14。この時点で Gemini 3.1 Pro ($0.25/$1.00) との差は 2.5-5 倍まで縮まり、品質差を考えれば Opus の優位が出る場合がある。
有効コストの 3 層最適化
- 単価層:どのモデルをどの割合で使うか(Pattern 2 Cascade で決まる)
- キャッシュ層:Prompt / Context caching で再計算を減らす
- アーキテクチャ層:Router で不要な高額モデル呼び出しを切る、Verifier を抜き打ちサンプリングに変える
3層を掛け合わせると、同じ品質を 1/5〜1/10 のコストで出すことが現実的になる。逆にこの最適化を放置し、全タスクを Opus 4.7 xhigh で走らせる設計は、品質保険料を過剰に払っている状態と言える。
Mythos 時代:Access-restricted フロンティアが問うもの
Mythos がもたらす構造変化は、ベンチマーク表に書かれないところにある。
Anthropic は Mythos を「API で誰でも買えるモデル」にしなかった12。Project Glasswing コンソーシアムに加盟する選定企業のみが触れる。同様の制限モデルは今後増える可能性が高い——フロンティアモデルが 0-day を自律発見できる段階11に入った以上、無制限公開は安全保障上のリスクになるからだ。
この構造は、オーケストレーション設計に 2 つの含意を持つ。
1. 単一ベンダー依存は事業リスクに変わる
「全部 Opus 4.7 でいい」という発想は、Anthropic の方針転換ひとつで全停止する脆弱な構成だ。Mythos がコンソーシアム会員向けに限定された事実は、「次世代モデルは自分の会社に開放されるとは限らない」ことを示している。常に複数ベンダーの上に成り立つスタックを組むことが、技術選定ではなく事業継続性の問題になった。
2. オーケストレーションはポートフォリオ戦略である
4 パターンのいずれを採用するにせよ、本質はモデルの組み合わせで価値を出すことである。これは金融のポートフォリオと構造が同じだ。
- Router = 適材適所配分(asset allocation)
- Cascade = 段階的リスク露出
- Verifier = クロスチェックによるリスク抑制
- Specialist Chain = バリューチェーン最適化
「一番強い株」を持つのではなく「組み合わせで期待リターンを最大化する」という発想が、AI スタックにそのまま当てはまる時代が来た。
まとめ:単一モデル思考から、ポートフォリオ思考へ
2026 年 4 月の大豊作が突きつけた事実はシンプルである。どのモデルも、どれかの指標で勝ち、どれかの指標で負ける。勝者が固定された時代に通用した「最強モデルを選ぶ」という意思決定プロトコルは、そのままでは壊れる。
代わりに必要なのは、次の 3 つの視点である。
- キャラクター認識:各モデルを「何屋さんか」として理解する。GPT-5.5 はエージェント、Opus 4.7 は長距離 SWE、Mythos は専門家、Gemini 3.1 Pro は安価かつ多才、Grok 4.3 はリアルタイム。
- 組み合わせ設計:Router / Cascade / Verifier / Specialist Chain の 4 パターンを、ユースケースに合わせて選ぶ。
- 有効コストとリスク分散:単価ではなく品質当たりのコスト、そして単一ベンダー依存を避けるポートフォリオ思考。
記事を閉じる前に、まず手元のタスクを一つ選び、そのタスクがどのパターンに当てはまるかを言語化してみてほしい。「このタスクは Router で十分」「これは Verifier を挟まないと怖い」と言えた瞬間から、単一最強論の呪縛は解ける。オーケストレーションは抽象概念ではなく、1 タスク 1 設計から積み上がっていく実務である。
Footnotes
xAI quietly tests Grok 4.3 beta on official website — KuCoin News ↩ ↩2
OpenAI Releases GPT-5.5, 82.7% on Terminal-Bench 2.0 — MarkTechPost ↩
Anthropic’s Claude Mythos Preview Changes Cyber Calculus — Foreign Policy ↩ ↩2
Anthropic Releases Claude Mythos Preview with Cybersecurity Capabilities but Withholds Public Access — InfoQ ↩ ↩2