
2026年5月5日、OpenAI は GPT-5.5 Instant を ChatGPT の新しいデフォルトモデルとして展開し始めた12。GPT-4.5 以来初の完全再訓練ベース GPT-5.5 が API に出てから、わずか 2 週間後の動きである3。今回の刷新で何が変わったかは大きく 3 つに集約される。 high-stakes 領域でのハルシネーションが GPT-5.3 Instant 比で 52.5% 削減 されたこと、過去会話・ファイル・Gmail を横断する長期記憶が標準搭載されたこと、そして応答スタイルが「より簡潔・絵文字控えめ・追従質問の少なさ」へと調整されたこと12。本記事では、なぜこのタイミングで Instant が単独ニュースになったのかという背景から始め、モデルカード比較、比較優位性、想定ユースケースの順に整理する。

なぜ今 Instant なのか — リリース背景とモチベーション
GPT-5.5 ファミリーのロールアウトは、わずか 2 週間に圧縮された 3 段ロケットである。4月23日 に GPT-5.5 ベースモデルが発表され(GPT-4.5 以来初のフルリトレーン)、翌 4月24日 に GPT-5.5 と GPT-5.5 Pro が API で一般提供3。そして 5月5日 、ChatGPT の既定モデルが GPT-5.3 Instant から GPT-5.5 Instant へ切り替わった1。GPT-5.3 Instant は 3 ヶ月のみ有料ユーザー向けに維持され、その後は Instant 系列が GPT-5.5 に統一される予定だ2。
「Instant の更新」が単独で大きなニュースになる理由は、ChatGPT の既定モデルが社会的インフラに近づいているからだ。フリープランから Pro まで、何億人ものユーザーが意識せずに触れる「最初のモデル」を変えるという行為は、API モデルを 1 つ追加するのとは桁違いの波及がある。OpenAI が GPT-5.5 ベース直後にあえて Instant 専用のメッセージングを切り出したのは、そのインパクトを管理するためでもある1。
中核モチベーションは、ChatGPT がローンチされた 2022 年以来繰り返し指摘されてきた ハルシネーション問題 への直接的な対処である2。OpenAI の公開する数値では、 high-stakes プロンプト(医療・法律・金融)におけるハルシネートされたクレームが GPT-5.3 Instant ベースライン比で 52.5% 削減 され、ユーザーがフラグした会話の事実誤りも 37.3% 削減 されたとされる12。HealthBench 総合は 49.6 から 51.4、HealthBench Professional は 32.9 から 38.4 へと上がり、特にプロフェッショナル領域での改善幅が大きい2。
加えて UX 面の調整も明示されている。応答は「冗長な絵文字を排し、追従質問を減らし、要点を外さずに簡潔にする」方向へ寄せられた2。これは「会話を続けさせる AI」から「タスクを終わらせる AI」へのスタイルシフトとも読める。
モデルカードを並べて見る
GPT-5.5 Instant の位置を理解するには、競合モデルとモデルカードを並べるのが早い。価格・コンテキスト・ベンチマーク・機能の 4 軸で見ていく。
GPT-5.5 Instant モデルカード
| 項目 | 値 |
|---|---|
| API 識別子 | gpt-5.5 (reasoning.effort を minimal/low に設定すると Instant 動作)4 |
| Context window (API) | 1,000,000 tokens(272K 超過分は割増価格)4 |
| Context window (Codex) | 400,000 tokens3 |
| Max output | 128,000 tokens4 |
| Knowledge cutoff | 2025-12 3 |
| マルチモーダル | テキスト・画像・音声・動画(統合アーキテクチャ)3 |
| 価格 (Standard) | 入力 $5.00 / 1M、出力 $30.00 / 1M4 |
| 価格 (Batch / Priority) | Batch 50% オフ、Priority 2.5 倍4 |
| キャッシュ | $0.50 / 1M(90% 引き)5 |
| Intelligence Index | 60/100(Artificial Analysis、xhigh tier 計測)5 |
なお ChatGPT 側の利用枠は、無料プランで 5 時間あたり 10 メッセージ、Plus で 3 時間あたり 160 メッセージ、Pro / Business は実質無制限となっている4。
競合モデルカード早見表
| モデル | 入力 $/1M | 出力 $/1M | Context | 出力上限 | SWE-bench | リリース |
|---|---|---|---|---|---|---|
| GPT-5.5 Instant | 5.00 | 30.00 | 1M | 128K | (注 1) | 2026-05-05 |
| Gemini 3 Flash | 0.50 | 3.00 | 1M | - | 78.0% | 2025-12-176 |
| Gemini 3.1 Flash-Lite | 0.25 | 1.50 | 1M | - | - | 2026 上半期7 |
| Claude Haiku 4.5 | 1.00 | 5.00 | 200K | 64K | 73.3% | 2025 後半8 |
注 1: GPT-5.5 ベースの SWE-bench Verified スコアは公開されていないが、関連ベンチで Terminal-Bench 2.0 82.7%、OSWorld-Verified 78.7%、Tau2-bench Telecom 98.0% を記録している3。Instant 単独の SWE-bench 数値は OpenAI から公表されていない。
Instant 固有のベンチマーク(vs GPT-5.3 Instant)
| ベンチマーク | GPT-5.5 Instant | GPT-5.3 Instant |
|---|---|---|
| 高ステークス領域の幻覚クレーム削減率 | -52.5% | (基準) |
| ユーザーフラグ会話の事実誤り削減率 | -37.3% | (基準) |
| HealthBench | 51.4 | 49.6 |
| HealthBench Professional | 38.4 | 32.9 |
| AIME 2025 | 81.2 | 65.4 |
| MMMU-Pro | 76.0 | 69.2 |
ベンチマーク表を読むときの注意は 2 つある。1 つ目は Instant 固有の数値が限定的であることだ。Artificial Analysis の Intelligence Index 60/100 は GPT-5.5 (xhigh) 計測で、Instant モードのスコアではない5。2 つ目は、ハルシネーション削減率が OpenAI の自社評価セットによる数値で、第三者の独立評価はまだ到着していないことだ。一次情報の信頼度は高いが、外部監査が積み上がるまでは「公式が主張する改善幅」として読むのが妥当である。
整理すると、GPT-5.5 Instant は「高単価・高知能・高統合」のティアにいる。一方の Gemini 3 Flash や Claude Haiku 4.5 は「低単価・高速・特化」のティアで、価格レンジは Gemini Flash で出力 $3、Haiku 4.5 で $5、GPT-5.5 Instant の $30 と一桁違う468。同じ「フラッシュ/インスタント/ハイクー」というカテゴリ名でも、戦っている軸が違うことが見えてくる。
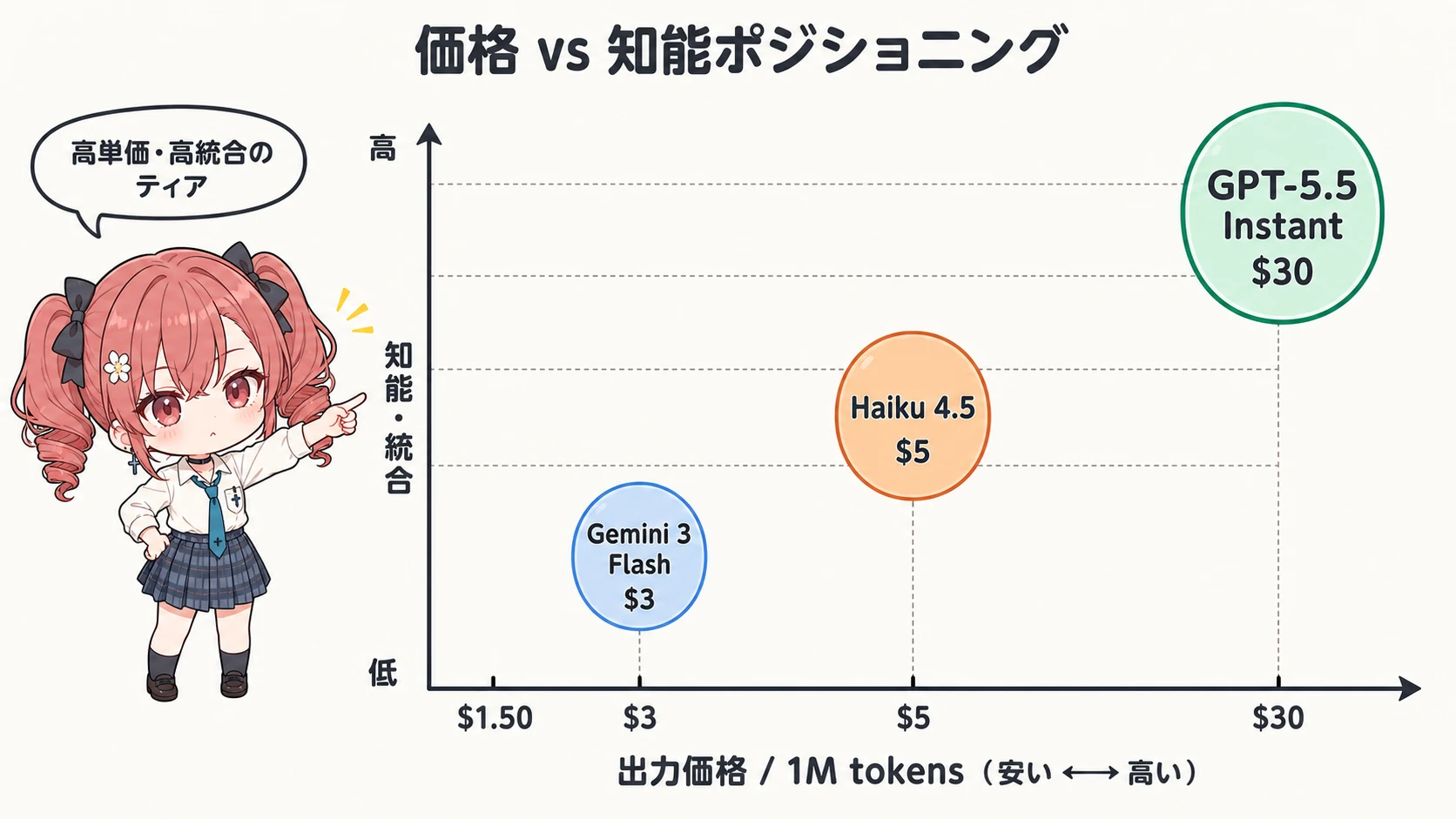
比較優位性 — どこで GPT-5.5 Instant を選ぶ理由になるか
価格表だけ見れば、GPT-5.5 Instant は競合 Flash/Haiku に対して明確に高い。にもかかわらず多くのユーザーがこれを使うのは、価格以外の 3 つの軸——ディストリビューション、ハルシネーション抑制、OS 級統合——でリードしているからだ。
Distribution Edge:「ChatGPT の既定」というレバレッジ
GPT-5.5 Instant の最大の強みは、 ChatGPT のフリープランから Pro まで、すべてのユーザーが意識せず最初に触るモデル だという点だ1。API 単価で勝負するモデルではなく、製品としての到達範囲で勝負しているとも言える。Gemini Flash や Haiku 4.5 は「明示的に呼び出す API モデル」だが、GPT-5.5 Instant は「日常で触る AI そのもの」になった。プロダクト戦略上、この差は単純なベンチスコアでは測れない。
High-Stakes Trust:医療・法律・金融でのファクト性能
high-stakes 領域でのハルシネーション 52.5% 減と、HealthBench Professional の +5.5pt は、業務での「使ってよい AI」と「補助的な AI」の境界線を引き直す数字だ12。医療従事者が初期的な文献検索に使う、法務担当者が契約書の論点抽出に使う、金融アナリストが決算サマリのドラフトに使う——こうした業務で「事実誤り 37.3% 減」は無視できない改善幅である。Gemini Flash や Haiku 4.5 は速度とコストで優れるが、 high-stakes 領域に特化したファクト性能の改善を前面に押し出してはいない。
Memory & Integration:OS 級の統合という非対称優位
GPT-5.5 Instant は 過去会話・保存ファイル・Gmail を横断検索して回答に組み込む 2。ユーザーは「どの context が使われたか」を画面上で確認でき、不要なものは削除できる。プライベートモードに相当する「Temporary chat」では、その参照自体を切れる。
これは API 一本で勝負する Gemini Flash や Haiku 4.5 が原理的に再現しにくい優位だ。OpenAI は Microsoft 365 / ChatGPT Apps / カスタム GPTs といったエコシステムを持ち、Gmail 連携も既に組み込まれている。 モデル単体の知能ではなく「ユーザーのデジタル痕跡を文脈にできる権利」 が GPT-5.5 Instant の差別化になっている。
価格は不利:ここを直視する
公平を期すと、GPT-5.5 Instant の API 単価は競合より明確に高い。出力 $30/1M は Gemini 3 Flash の 10 倍 、Claude Haiku 4.5 の 6 倍 だ468。さらに Gemini 3.1 Flash-Lite は出力 $1.50/1M で、 20 倍 の差になる7。大量バッチ要約、ログ分類、コスト感度の高いコンテンツ生成といった用途では、価格差が決定打になり GPT-5.5 Instant を選ぶ理由はほぼない。
つまり選択は「価格で割り切る用途」と「統合と精度で価値を生む用途」に二極化する。中間層(速度と価格をバランスしたい用途)では Haiku 4.5 や Gemini 3 Flash が依然として強い競争力を保つ。

想定ユースケース 5 選
GPT-5.5 Instant が最も活きるのは、 「速度 × 精度 × エコシステム統合」 が同時に求められる文脈である。逆にコスト感度が支配する用途や、独自ファインチューン必須の領域では他モデルに譲るべき。具体的に 5 つ挙げる。
1. 医療・法律・金融の業務 Q&A
HealthBench Professional の +5.5pt と high-stakes ハルシネーション 52.5% 減が直接効くのが、医療・法務・財務の現場知識タスクである12。臨床ガイドラインの要点抽出、判例検索の初期スクリーニング、決算資料の論点整理など、「最終判断は人がやるが、初稿を AI に任せたい」業務との相性が良い。Pro / Business プランなら ChatGPT で実質無制限に回せる4。
2. 長期記憶を活かしたパーソナルアシスタント
過去会話・Gmail・保存ファイルを横断する記憶機能は、 「自分専用の AI」 の体験を一段引き上げる2。「先週相談したあの企画、どこまで詰めたっけ?」「3 月のメールに添付されていた請求書の合計は?」——こうした横断クエリが、外部ツールに飛ばずに答えとして返ってくる。
3. ChatGPT を業務 UI として使う社内ツール
Plus / Pro 課金で API 構築をスキップして即運用 できるのは、小規模チームには大きなメリットだ。カスタム GPTs / ChatGPT Apps と組み合わせれば、社内 Q&A、議事録ドラフト、メール下書きなどを開発工数ゼロで提供できる。GPT-5.5 Instant がデフォルトになったため、「ChatGPT を開けば最新精度が使える」状態が前提になる。
4. マルチモーダル対話
GPT-5.5 はテキスト・画像・音声・動画を 単一アーキテクチャで処理 する3。Instant モードでも入出力モダリティは同等で、たとえばホワイトボード写真を撮って議事録化する、図を見せて要約する、音声入力でメモを取る、といったワークフローがレイテンシを抑えながら実現できる。
5. 機密相談と Temporary chat
「この相談だけは履歴を残したくない」という要件に対して、GPT-5.5 Instant は Temporary chat モードで context 参照と履歴保存をオフ にできる2。長期記憶機能の裏返しとして、明示的に切れる仕組みも組み込まれているのは、業務利用での受容性を高める設計である。
不向きな用途
公平のため、選ぶべきでないシナリオも書いておく。
- 大量バッチ要約・ログ分類 — Gemini 3.1 Flash-Lite(出力 $1.50/1M)の方が経済合理的7
- IDE 内コーディングエージェント — Claude Sonnet 4.5 / Opus 4.7 / GPT-5.5 Pro が SWE-bench で上8
- リアルタイム情報検索(株価・速報・SNS) — Grok 系列のリアルタイムデータ統合に劣る
まとめ — 「Instant」というカテゴリ自体の意味が変わった
数年前まで「Instant / Flash / Haiku」は 軽量・廉価・代替 の代名詞だった。フラグシップが本命で、軽量ティアは「コストの都合で諦める層」のためにあった。GPT-5.5 Instant のリリースは、この前提を反転させた。Instant が 「フラグシップを高速で出す」 へ意味を変え、ChatGPT の既定モデルを担うところまできた。同じ流れは Gemini 3 Flash や Claude Haiku 4.5 にも見え、軽量ティアこそが業務利用の主戦場になっている。
ユーザー側の意思決定軸も変わる。「価格で勝つか、統合で勝つか」の二極化が進み、中間で迷う領域は徐々に縮んでいく。GPT-5.5 Instant は 統合側の極 に明確に振った。次に注目すべきは、GPT-5.5 Instant と Pro の間でタスクの難度に応じて自動的にルーティングする運用設計だろう(既存記事 GPT-5.5・Opus 4.7・Gemini 3.1 Pro・Grok 4.3+Mythos:「最強モデル」を捨てオーケストレーションで勝つ でこのオーケストレーション論を扱っている)。Instant が「軽量」ではなく「速いフラグシップ」になった以上、ルータの仕事は減らない。むしろ、軽量ティアの精度が上がったことで、ルーティング判定の閾値設計こそが新しい設計問題になっていく。
参考文献
Footnotes
OpenAI releases GPT-5.5 Instant, a new default model for ChatGPT — TechCrunch - 2026-05-05 リリース報道、ハルシネーション 52.5% 削減、GPT-5.3 Instant の段階廃止 ↩ ↩2 ↩3 ↩4 ↩5 ↩6 ↩7 ↩8 ↩9
OpenAI’s new GPT-5.5 Instant makes ChatGPT smarter, with more concise and reliable responses — SiliconANGLE - HealthBench / AIME / MMMU-Pro 数値、長期記憶・Gmail 連携、Temporary chat、応答スタイル調整 ↩ ↩2 ↩3 ↩4 ↩5 ↩6 ↩7 ↩8 ↩9 ↩10 ↩11 ↩12 ↩13
Introducing GPT-5.5 — OpenAI - 2026-04-23 公式発表。base モデルと API 一般提供のタイムライン、Codex の 400K context、知識カットオフ等 ↩ ↩2 ↩3 ↩4 ↩5 ↩6 ↩7
How to Access and Use GPT-5.5 Instant: ChatGPT + API Guide — apidog - API 識別子、価格、ChatGPT 利用枠、
reasoning.effortパラメータ ↩ ↩2 ↩3 ↩4 ↩5 ↩6 ↩7 ↩8 ↩9GPT-5.5 (xhigh) - Intelligence, Performance & Price Analysis — Artificial Analysis - Intelligence Index 60/100、出力速度、TTFT、blended pricing ↩ ↩2 ↩3
Introducing Gemini 3 Flash — Google - Gemini 3 Flash の価格・SWE-bench 78%・3x 高速化 ↩ ↩2 ↩3
Gemini 3.1 Flash-Lite Review 2026 — AIMLAPI - Gemini 3.1 Flash-Lite の $0.25 / $1.50 価格 ↩ ↩2 ↩3
Introducing Claude Haiku 4.5 — Anthropic - Claude Haiku 4.5 の価格・context・SWE-bench 73.3%・速度 ↩ ↩2 ↩3 ↩4