
2026 年 5 月 7 日、OpenAI は gpt-realtime-2 を発表した1。リアルタイム音声 API スタックの世代交代を狙う一手で、開発者・PdM の関心は「結局どれを採用すべきか」に集まっている。本記事では主要 4 社(OpenAI / Google / ElevenLabs / Cartesia)の最新モデルを Big Bench Audio・Full Duplex Bench・レイテンシ・価格・統合機能 の 5 軸で横並び比較し、gpt-realtime-2 のブレイクスルーが「単一ベンチマーク 1 位」ではなく別の場所にあることを定量で示す。
gpt-realtime-2 の発表内容を 1 分で
OpenAI は単一モデルではなく、3 モデルを同時投入した2。
- gpt-realtime-2: GPT-5 級 reasoning を備えた音声対話モデル。128K コンテキストと 5 段階 reasoning effort(minimal / low / medium / high / xhigh)を持つ
- gpt-realtime-translate: 70+ 入力 → 13 出力言語のリアルタイム翻訳特化。$0.034 / 分
- gpt-realtime-whisper: ストリーミング STT、レイテンシ制御可能。$0.017 / 分
gpt-realtime-2 本体の価格は $32 / 1M audio input tokens(cached $0.40)、$64 / 1M audio output tokens で、前世代 gpt-realtime-1.5 から据え置き3。新機能の目玉は 並行ツール呼び出しと 「checking your calendar」のような思考実況 narration で、待ち時間に発話を埋める設計が公式に明文化された2。
比較対象 4 モデルと評価軸
リアルタイム音声 API はもはや単一カテゴリではない。「全領域カバー」と「特定領域特化」に分かれており、横並び比較するなら評価軸を分離する必要がある。
| モデル | 種別 | 主な強み |
|---|---|---|
| OpenAI gpt-realtime-2 | Speech-to-Speech (full) | 推論 + 統合性 |
| Google Gemini 3.1 Flash Live | Multimodal native audio | 価格 + レイテンシ |
| ElevenLabs Conversational AI | TTS + Agent runtime | TTS 品質 + 短時間導入 |
| Cartesia Sonic-3 | TTS 専門 (SSM) | 超低レイテンシ TTS |
評価軸は次の 5 つに固定する。
- Speech Reasoning — Big Bench Audio(音声入力での推論精度)
- Conversational Dynamics — Full Duplex Bench(ターンテイク、ポーズ処理、割り込み復帰)
- レイテンシ — TTFA / TTFB
- 価格 — $/h 換算(input + output)
- プロダクション統合 — SIP / MCP / 画像入力 / parallel tool calls
数値はすべて Artificial Analysis のリーダーボードを 2026-05-09 時点で参照4。OpenAI 自社報告値とも相互照合してある。
ベンチマーク横並び — Speech Reasoning と Full Duplex
Speech Reasoning は Step-Audio R1.1 が 1 位
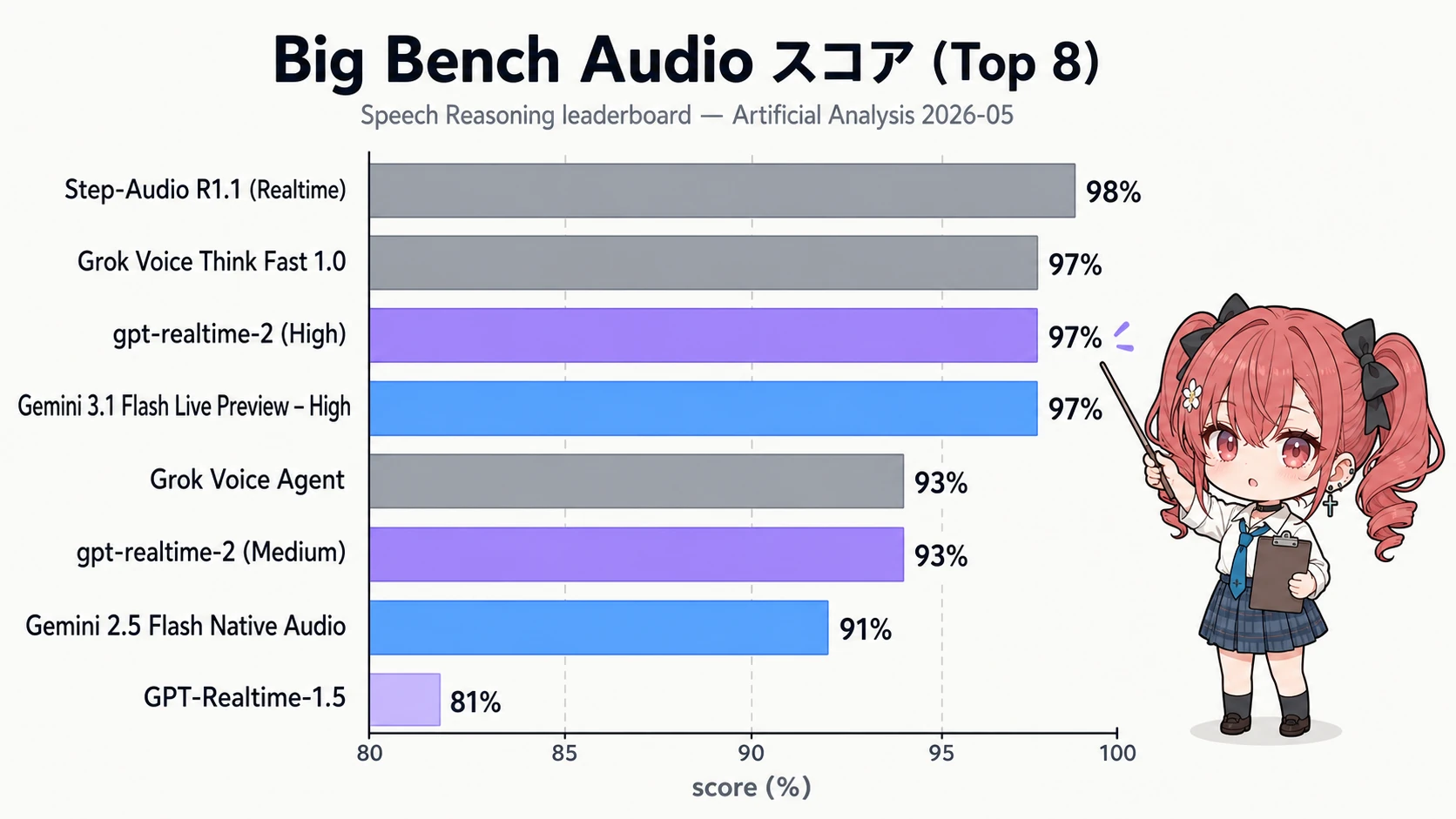
Big Bench Audio(1,000 問の音声推論ベンチ)の上位は次の通りである4。
| 順位 | モデル | スコア | プロバイダ |
|---|---|---|---|
| 1 | Step-Audio R1.1 (Realtime) | 98% | StepFun |
| 2 | Grok Voice Think Fast 1.0 | 97% | xAI |
| 3 | gpt-realtime-2 (High) | 97% | OpenAI |
| 4 | Gemini 3.1 Flash Live Preview – High | 97% | |
| 5 | Grok Voice Agent | 93% | xAI |
| 7 | Gemini 2.5 Flash Native Audio Dialog Thinking | 91% | |
| 9 | GPT Realtime(無印・前世代) | 83% | OpenAI |
| 10 | GPT-Realtime-1.5 | 81% | OpenAI |
純 Speech Reasoning では Step-Audio R1.1 がトップで、gpt-realtime-2 (High) は 1 ポイント差の 3 位タイ。それでも 前世代 1.5 比 +15.2 ポイント2 というジャンプ幅は他社の世代交代を上回る。
Full Duplex Bench は gpt-realtime-2 が単独 1 位
会話流暢性(ターンテイク、ポーズ処理、割り込み復帰の総合スコア)を測る Full Duplex Bench では話が変わる。gpt-realtime-2 (Minimal) が 96.1% で 1 位5。Minimal モード(推論最小)でこのスコアを出している点が重要だ。推論に振らなくても会話のリズムは崩れない、という設計が反映されている。
つまり「推論で勝負」と「会話で勝負」は別軸であり、gpt-realtime-2 は 後者で他社を抜いた。
レイテンシと価格 — gpt-realtime-2 は単独最速でも最安でもない
レイテンシは Cartesia / ElevenLabs が圧勝
Time-to-First-Audio(最初の音声を返すまでの時間)を見ると、gpt-realtime-2 は決して速いほうではない4。
| モデル | TTFA | カテゴリ |
|---|---|---|
| Gemini 2.5 Flash Native Audio Dialog | 0.63 s | Speech-to-Speech |
| Grok Voice Agent | 0.78 s | Speech-to-Speech |
| Step-Audio R1.1 (Realtime) | 1.51 s | Speech-to-Speech |
| gpt-realtime-2 (Minimal) | 1.12 s | Speech-to-Speech |
| gpt-realtime-2 (High) | 2.33 s | Speech-to-Speech |
| Gemini 3.1 Flash Live Preview (High) | 2.98 s | Speech-to-Speech |
| Cartesia Sonic-2 (TTFB) | ~90 ms | TTS 単体 |
| ElevenLabs Flash v2.5 | <100 ms | TTS 単体 |
ここでの注意点は TTS 単体と Speech-to-Speech が桁違いの別物だ という事実である。Cartesia の 90 ms は「すでにある文字列を音声化する時間」で、gpt-realtime-2 の 1.12 s は「音声を聞いて意味を理解し、推論し、応答音声を返すまで」。比較する際は軸を揃える必要がある。
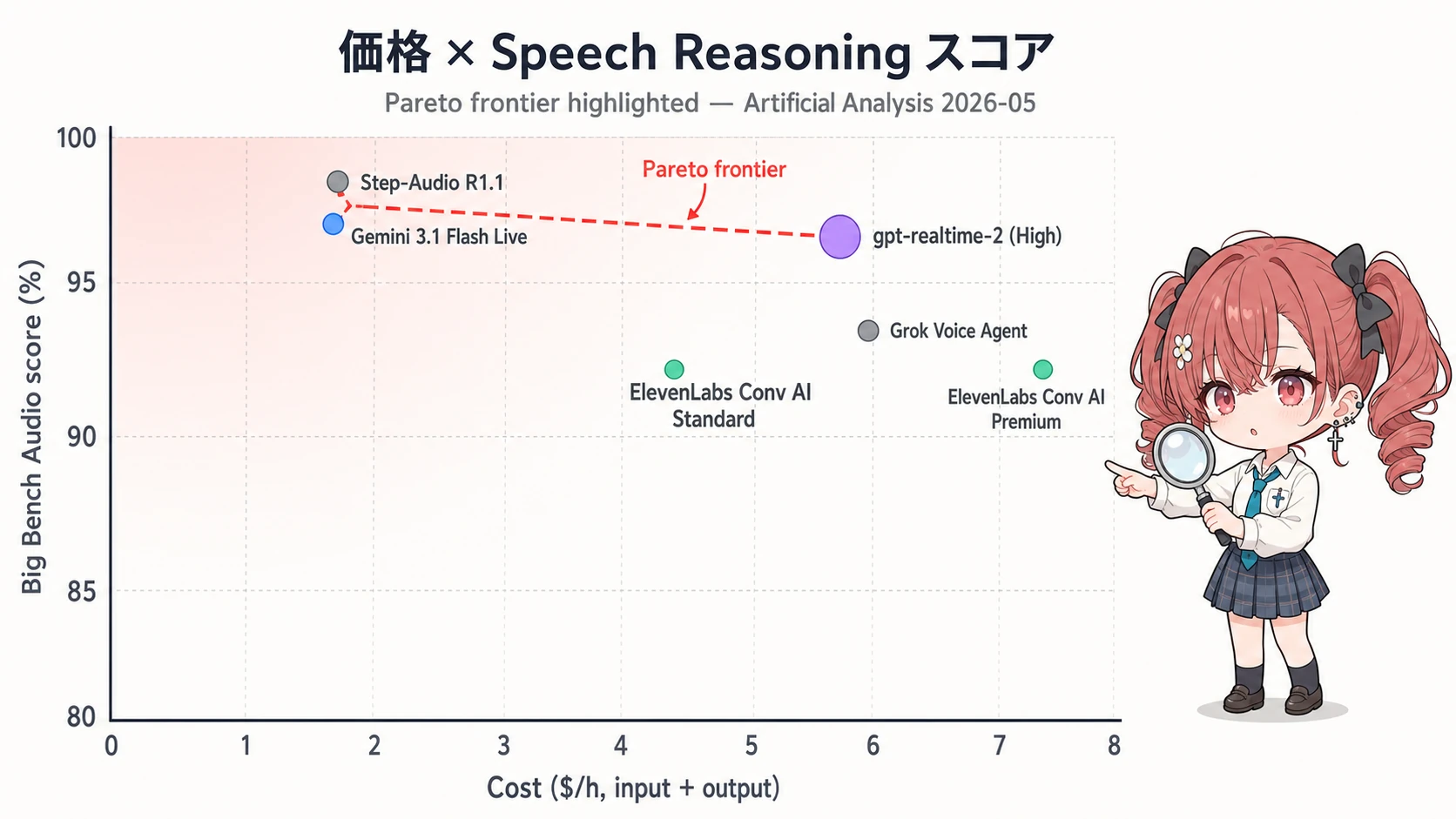
価格は Gemini Live と Step-Audio が安い
1 時間あたりの総コスト(入力 + 出力、Artificial Analysis 換算)4:
| モデル | $/h 概算 |
|---|---|
| Gemini 3.1 Flash Live (preview) | $1.73 |
| Step-Audio R1.1 | $1.75 |
| ElevenLabs Conv AI Standard | $4.80 |
| gpt-realtime-2 | $5.76 |
| Grok Voice Agent | ~$6.00 |
| ElevenLabs Conv AI Premium | $7.20 |
gpt-realtime-2 は中位である。Gemini 3.1 Flash Live は preview 中で API 利用が無料6、Step-Audio は計測上 1/3 強の価格。コスト最重視なら gpt-realtime-2 は第一候補にならない。
本当のブレイクスルーは「統合性」だ
ここまでで見えてくるのは、gpt-realtime-2 は単一指標で 1 位を取ったわけではない という事実。Speech Reasoning は Step-Audio に、レイテンシは Cartesia に、価格は Gemini に譲っている。
ではなぜ「ブレイクスルー」と呼ばれるのか。答えは プロダクション統合機能の同時達成 にある。
| 機能 | gpt-realtime-2 | Gemini 3.1 Flash Live | ElevenLabs Conv AI | Cartesia |
|---|---|---|---|---|
| WebRTC | ✅ | ✅ | ✅ | △ |
| WebSocket | ✅ | ✅ | ✅ | ✅ |
| SIP(電話直結) | ✅ | △ | △ | ❌ |
| Remote MCP server | ✅ | ❌ | ❌ | ❌ |
| 画像添付 in voice turn | ✅ | ✅ | △ | ❌ |
| 並行ツール呼び出し | ✅ | ✅ | △ | N/A |
| 思考実況 narration | ✅ | △ | ❌ | ❌ |
| 128K context | ✅ | (Live API 範囲) | N/A | N/A |
これまで「GPT-5 + ElevenLabs Flash + 自前 agent runtime + Twilio SIP」と 4 ベンダ統合 で組んでいた構成が、gpt-realtime-2 単体でほぼ同等以上になった。Remote MCP(任意ツールサーバを URL で繋ぐ)と SIP(電話網直結)の両方を持つのは現状 gpt-realtime-2 だけで、これが乗算的な開発負荷削減を生む。
実例として Zillow の本番ベンチでは call success rate が 69% → 95%(+26 ポイント) に跳ねた7。これは単に推論が賢くなった結果ではなく、ツール呼び出しと割り込み復帰と SIP 統合が同時に効いた数値だと OpenAI は説明している。
つまりブレイクスルーの定義は次のようになる。
Big Bench Audio 96.6%(3 位タイ)かつ Full Duplex Bench 96.1%(1 位)かつ SIP + MCP + 128K を同時に満たすモデルは現状 gpt-realtime-2 のみ。
単独最強ではない。同時最強 こそが本質的差別化点である。
開発者・PdM の選び方 — ユースケース別の推奨
「全部 gpt-realtime-2 で良い」というわけではない。ユースケース別に整理すると次のようになる。
| ユースケース | 第一候補 | 理由 |
|---|---|---|
| 24h 稼働コールセンター | gpt-realtime-2 | SIP 直結 + 推論 + Zillow 実績 |
| コスト重視・PoC | Gemini 3.1 Flash Live (preview) | API 無料、Big Bench Audio も 97% |
| 多言語ライブ翻訳 | gpt-realtime-translate | $0.034/min で 70→13 言語独走 |
| 超低レイテンシ TTS(読み上げ・通知) | Cartesia Sonic-3 / ElevenLabs Flash | 90 ms / sub-100 ms 級 |
| エージェント PoC を 1 週間で立ち上げ | ElevenLabs Conv AI Premium | gpt-4o + Flash v2.5 統合済み runtime |
スイッチングコストが低いのは ElevenLabs(LLM 差し替え可能)と Gemini(Google Cloud 上で完結)。ロックインを許容する代わりに統合の楽さを取るのが gpt-realtime-2 だ。設計判断はここで分かれる。
本記事の限界と未解決事項
公開情報の集約として、次の点はカバーできていない。
- OpenAI 公式 announcement page は WebFetch で 403。数値は MarkTechPost / DataCamp / latent.space / Artificial Analysis の相互照合で確認している
- 日本語専用ベンチマーク が 4 社いずれも未公開。日本市場での本番性能は実機検証が必要
- Artificial Analysis の計測リージョン・時刻 が一部未明記。本番環境のレイテンシは別途計測必須
- Cartesia Sonic-3 の Speech-to-Speech 統合計画は未公開。現状は TTS 専業
- Gemini 3.1 Flash Live の本番価格は preview 終了後に再評価必要
まとめ
gpt-realtime-2 のブレイクスルーは「単一指標 1 位」ではなく「reasoning × full-duplex × production stack の 3 条件を一つの API で同時に揃えた」点にある。Step-Audio や Cartesia のような特化モデルが個別軸で勝っていても、プロダクション統合の総合性能で gpt-realtime-2 を超えるモデルは現状存在しない。
次に測るべきは「実機での日本語 latency / 日本語 WER」「本番 SLA でのコスト最適化」「MCP サーバ群の運用負荷」の 3 点だ。voice AI を業務利用する組織にとって、ここから先は自社ワークロードでベンチを取りに行くフェーズに入った。
参考文献
Footnotes
OpenAI Releases Three Realtime Audio Models — MarkTechPost (2026-05-08) — gpt-realtime-2 / translate / whisper の 3 モデル発表まとめ。 ↩
Advancing voice intelligence with new models in the API — OpenAI — 公式 announcement。Big Bench Audio +15.2 pt と仕様の一次出典(直接 fetch 不可、リンク参照)。 ↩ ↩2 ↩3
OpenAI API Pricing 2026 — TokenMix — gpt-realtime-2 価格 $32/$64 /M tokens の確認。 ↩
Speech-to-Speech leaderboard — Artificial Analysis — Big Bench Audio ランキング、TTFA、$/h 換算の一次出典(2026-05-09 参照)。 ↩ ↩2 ↩3 ↩4
AINews: GPT-Realtime-2, -Translate, -Whisper — latent.space — Full Duplex Bench Conversational Dynamics 96.1% の出典。 ↩
Gemini 3.1 Flash Live API Quickstart Guide — LaoZhang AI — Gemini 3.1 Flash Live preview 期間中の無料利用と制限。 ↩
OpenAI launches GPT-Realtime-2 — TheNextWeb / Heyloha Blog — gpt-realtime-2 — Zillow の call success rate 69% → 95% 事例。 ↩