
プロンプトは「手順書」から「契約書」へ:GPT-3.5からGPT-5.5までの公式ガイド変遷と移行実践
はじめに:同じプロンプトを使い回した日に起きること
GPT-4 時代に磨き上げた system prompt を、そのまま gpt-5.5 に貼り替えてみる。すると、よくこういう挙動に出会う。
- 質問にすぐ答えず、毎回 3〜5 回検索してから語り始める
- 「step by step に考えよ」と書いたせいで、中間推論を律儀にユーザへ全部見せてくる
- 「絶対に〜してはいけない」を盛り過ぎて、本来許してよい質問にまで refusal が出る
- JSON の schema を prompt で長々と説明しているのに、enum を勝手に増やして返す
- 出力が長過ぎて、本筋を読むまで時間がかかる
モデルを gpt-4o に戻すと、これらは起きない。つまり「モデルが劣化した」のではなく、 モデルが従う対象が変わった ということだ。
OpenAI の公式ガイドを GPT-3.5 から gpt-5.5 まで通読すると、プロンプト最適化の重心が「手順を並べること」から「成果物の契約を書くこと」へきれいに移動している。そして Anthropic の Claude Opus 4.7、Google の Gemini 3 Pro / 3.1 Pro の最新ガイドも、ベンダーごとの語彙は違えど同じ方向にそろってきた12。
前半でこの思想変遷を整理し、後半で旧プロンプトを GPT-5.5 向けに書き直すための手順を、テンプレート・Before/After・チェックリストで提示する。
前半:思想変遷編 — 「指示文」が「運用契約」になるまで
GPT-3.5 / GPT-4:明示・反復・few-shot の時代
OpenAI の archived cookbook「How to format inputs to ChatGPT models」は、当時の前提を率直に書いている3。
- 重要な指示は system だけに置かず、user にも再掲する
- とくに
gpt-3.5-turbo-0301は system 指示への追従が弱く、人間にしか分からない曖昧な表現を避ける - Few-shot で「期待する形」を見せる方が、説明文よりも安定する
つまりこの時代のプロンプトは、モデルを誘導する道具だった。書き手は、モデルが drift しないよう、同じ制約を複数の場所に書き、足りなければ例を増やした。GPT-4 では system への追従と複雑指示の理解が改善し、人手評価でも GPT-3.5 より 70.2% 好まれるようになったが、思想そのものは大きくは変わらない4。temperature を 0 にして安定を取り、top_p を絞り、足りないところを few-shot で補う。これが「プロンプトエンジニアリング」と呼ばれていた仕事の中心だった。
この世代の前提を端的に言うとこうなる。
プロンプトの質 = どれだけモデルが迷わないように先回りして書けるか
GPT-4o:マルチモーダルとStructured Outputsの導入
GPT-4o は、GPT-4 Turbo 級の英語テキスト・コード性能を、より低コスト・低レイテンシで配達するモデルとして登場した5。性能の話より、プロンプト設計の文脈で重要なのは、このタイミングで Structured Outputs が実用域に入ったことだ6。
これまで「JSON で返して」「絶対にこの schema 通りに」と prompt で脅していた部分が、API 側の response_format / json_schema で扱えるようになった。つまり schema 強制は prompt の責任ではなくなった。プロンプトには「何を返すか」のセマンティクスだけを書き、構造の責任は API に逃がせる。
ここから少しずつ、プロンプトは「全部を書く仕様書」ではなくなっていく。
GPT-4.1:literal な追従、long context、tool-as-API
本当の転換点は GPT-4.1 だった。OpenAI は GPT-4.1 を GPT-4o よりさらに literal に指示へ従うモデル として位置づけ、専用の prompting guide を公開している7。
ここで初めて、 手書きの system prompt よりも API 仕様を整えることの方が効く という主張が、公式ベンチマーク付きで提示された。
- ツール定義を system に長文で埋め込むより、
toolsフィールド経由で渡した方が SWE-bench Verified で約 2% 向上 - planning と verification の手順を明示すると、pass rate がさらに約 4% 改善
- 1M トークンの context window でも、指示は「先頭だけ」ではなく「先頭と末尾の両方」に置いた方が long context の使いこなしが安定する
- 長文の delimiter は JSON より Markdown / XML が好相性
これらは「うまく書くと当たる」ではなく「API に正しく載せると当たる」という性質の知見だ。GPT-4.1 以降、 プロンプトはモデル単体への呼びかけではなく、モデル+API への投入物 として設計する世界に入った。
同時に、コード編集での副作用が下がった点も見逃せない。GPT-4o では「指示外の余計な編集(extraneous edits)」が 9% 程度発生していたのが、GPT-4.1 では 2% まで落ちている8。literal に従うようになった結果、「気を利かせる量」が減って「線を超えない量」が増えたわけだ。これは指示文の書き方にもそのまま跳ね返る。曖昧に書けば本当に曖昧なまま実行され、過剰に書けば本当に過剰なまま律儀に守られる。
GPT-5:Responses API・reasoning.effort・verbosity
GPT-5 で導入された変化のうち、プロンプト設計の重心を一番動かしたのは、temperature 中心から reasoning.effort と text.verbosity 中心へ ノブが移ったことだ9。
reasoning.effort: モデルに「どれだけ考えるか」を渡す。minimal/low/medium/high(一部 surface でxhigh)の段階で、推論トークンの量を制御するtext.verbosity: 出力の長さを制御する専用ノブ。low/medium/highdeveloperrole: system と user の間に挟まる新ロール。業務契約は developer に、入力は user に、と役割分担が明示された
加えて OpenAI は GPT-5 系で Responses API への移行 を強く推奨している。同じプロンプトと設定でも、Responses API に乗せ替えるだけで SWE-bench が 3% 改善、previous_response_id を使った reasoning persistence では Tau-Bench Retail が 73.9% から 78.2% へ改善したと報告されている10。
「プロンプトを直す前に API を直すと、もうそれだけで効く」。この感覚は、GPT-4 時代までとは明らかに地続きでない。
CoT の扱いも変わる。古典的な Chain-of-Thought prompting は、十分大きいモデルに対して中間推論を外部化させることで複雑推論を引き上げる技法だった11。GPT-4.1 のような非 reasoning model では今も有効だが、GPT-5 系の reasoning model では raw な思考は API の外に直接は出てこない。中間手順を prompt 側で過剰に強制するより、目的・制約・成功条件・出力契約 を渡して、考え方はモデルに任せた方が良いとされている。
GPT-5.5:短く、成果志向で、停止条件を書く
そして gpt-5.5 の公式ガイドは、これまでの流れの帰結を一段はっきり言葉にしている12。
- 旧プロンプトを「持ち込んで足す」のではなく、 新しい baseline から書き直せ
- 詳細な step-by-step の手順、prompt 内の長い JSON schema、日付の明記、冗長な絶対命令は 削れ
- 代わりに
Goal/Success criteria/Constraints/Output/Stop rulesを短く書け - 必要なら短い
PersonalityとCollaboration styleを別ブロックで添えろ - 検索やツールは「毎回 N 回」ではなく retrieval budget や decision rule として書け
reasoning.effortの default はmediumだが、多くの実務 workload ではlowから試して足りなければ上げよtext.verbosity=lowは gpt-5.4 より相対的に強く短文化するので、UX の既定値として採用しやすい
つまり、「どう解くか」を減らし、「何が成功か」を増やすことが GPT-5.5 のプロンプト設計だ。process-heavy なテンプレートを持ち込むと、探索空間が硬直し、回答が機械的になり、無駄に検索ループが回ってトークンを食う。
ここまで来ると、プロンプトは「指示文」というより モデルに渡す運用契約 に近い。Goal は仕事の定義、Success criteria は受け入れ基準、Constraints は禁止事項、Output は納品様式、Stop rules は引き渡し条件。これは LLM の話というより、業務委託のスコープ書に似ている。
主要ノブの移動を一枚で
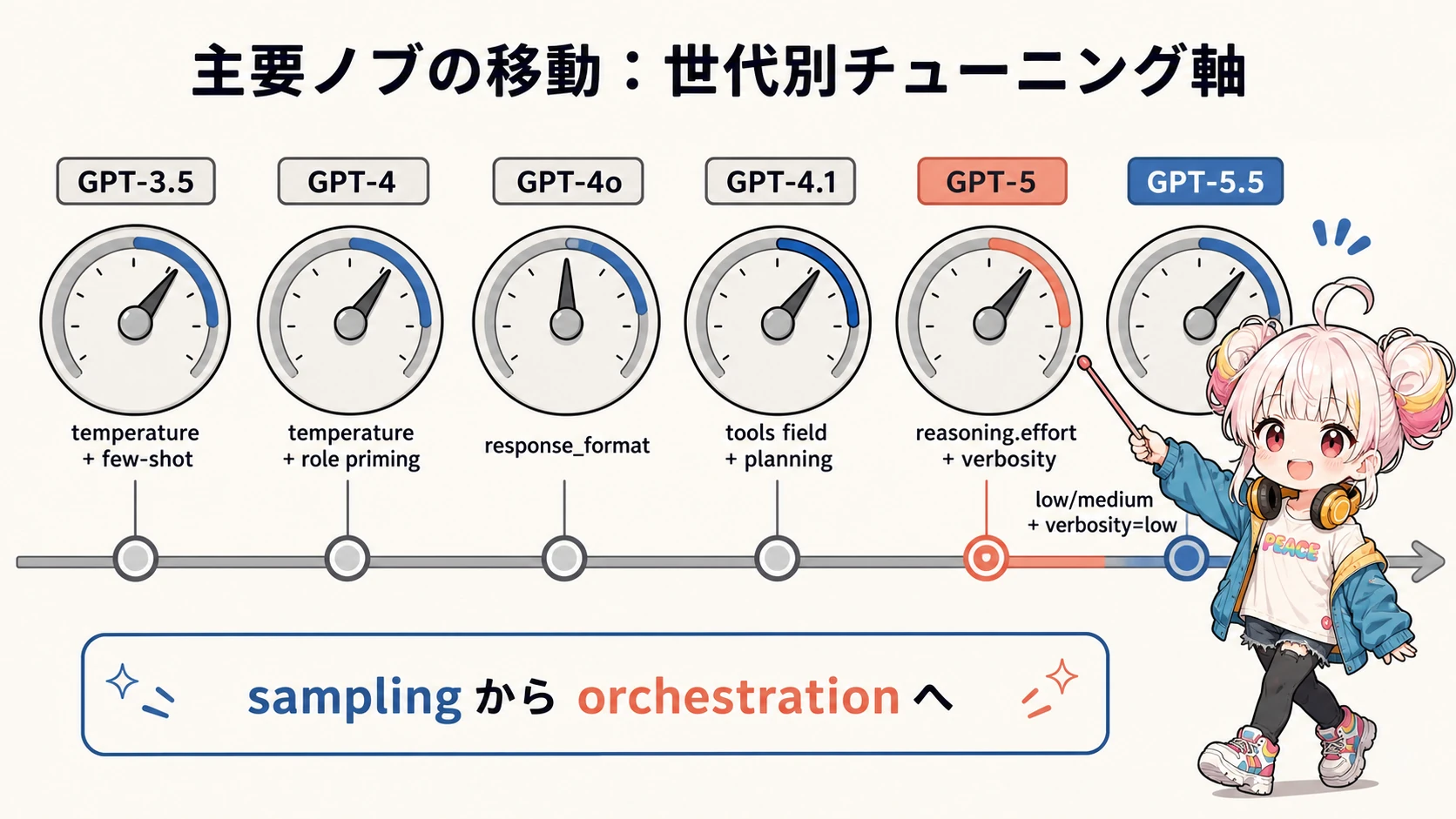
| 世代 | 主役のノブ | プロンプトに書くべきこと | プロンプトから外すべきこと |
|---|---|---|---|
| GPT-3.5 | temperature, few-shot | 役割、形式、例、重要制約の反復 | — |
| GPT-4 legacy | temperature, role priming | 役割、複雑指示、CoT 補助 | 過剰な再掲(system 追従が改善) |
| GPT-4o | response_format | 出力の意味、入力の文脈 | JSON schema の prose 説明 |
| GPT-4.1 | tools field, planning/verification | 段取り、検証手順、長文 delimiter | 手書き tool schema、曖昧な「気を利かせろ」 |
| GPT-5 | reasoning.effort, text.verbosity, developer role | 業務契約、eagerness 制御、preamble | 推論手順の強制、CoT の verbatim 強制 |
| GPT-5.5 | reasoning.effort=low/medium, verbosity=low | Goal / Success / Constraints / Output / Stop / Personality | step-by-step、ALWAYS search N times、日付直書き、長い絶対命令 |
書いてあるものと書かないもの、両方が変わっている。「足し算」での移行ではなく「書き直し」が必要になる根拠は、ここにある。
中盤:横並び比較編 — Anthropic と Google も同じ方向に揃った
OpenAI 単独の動きなら「そのベンダーの趣味」で片付けてもいい。だが、Anthropic と Google の最新ガイドを並べると、語彙の差を超えて 同じ方向に収束している ことが見える113214。
Anthropic Claude Opus 4.7
Opus 4.7 のプロンプトガイドが強調しているのは、ほぼ GPT-4.1〜GPT-5.5 の流れと同じ三本柱だ113。
- literal な指示遵守: 4.6 までは「だいたいこういう意味だろう」と推論で穴埋めしていたが、4.7 は書かれた通りに動く。曖昧に書けば曖昧に動く
- 例示の優越: トーンや形式は説明文より、2〜3 個の具体例で示す方が安定する。これは Pattern matching が説明指示より強いことの裏返し
- effort パラメータ: 4.7 で新設された intelligence 配分ノブ。OpenAI の
reasoning.effortと同じ目的 - コンテキスト工学: 500K トークンの prompt の真ん中に置いた事実は今でも拾い損ねる。重要な前提は task block の直前に「key facts」として再掲する
- tool definition が真の prompt: ユーザターンの文章よりも、tool spec の質が振る舞いを決める
- task budget (beta): agentic loop 全体に soft token ceiling を設けると、モデルが自ら残量を見ながら計画を縮める
「指示は薄く、例と契約を厚く、計算予算を渡す」。Anthropic の語り口はやさしいが、設計の骨格は OpenAI のものと交換可能だ。
Google Gemini 3 Pro / 3.1 Pro
Gemini 3 系は語彙が違って見えるが、結局のところ同じ方向を向いている214。
- thinking_level: 旧
thinking_budgetを置き換えるノブ。LOW/MEDIUM/HIGHを明示せよ、API の default はHIGH(つまり最も高価)なので明示しないとコストが膨らむ - temperature は default の 1.0 を維持せよ: 推論能力がこの設定で最適化されている。OpenAI が
temperatureを二次的なノブに格下げした文脈と、結論はほぼ同じ think silentlyを system instruction に置くとレイテンシが下がる: 内部推論はするが外には漏らさない指示- broad な禁止命令を避ける: 「do not infer」「do not guess」のような open-ended 指示はモデルが over-index して基本論理に失敗することがある。代わりに「与えられた追加情報を使え」と肯定形で書く
- コスト配分の目安: 60% を LOW、30% を MEDIUM、10% だけ HIGH に振り分ければ、月次の thinking token コストを 70〜75% 圧縮できると Google 側のガイドが示している
「effort/thinking レベルで質と速度を稼ぎ、温度は触らず、抽象的な禁止より具体的な肯定で書く」。OpenAI と Anthropic を読んだあとに Gemini を読むと、なじみのある思想にしか見えない。
3社横並び比較

| 観点 | OpenAI GPT-5.5 | Anthropic Opus 4.7 | Google Gemini 3 / 3.1 Pro |
|---|---|---|---|
| 思考量ノブ | reasoning.effort (low/medium/high/xhigh) | effort パラメータ | thinking_level (LOW/MEDIUM/HIGH) |
| 長さ・温度の扱い | text.verbosity で長さ制御。temperature は二次的 | 例示で長さ・トーンを示す | temperature=1.0 を維持推奨。thinking_level=LOW+“think silently”で短縮 |
| 指示遵守傾向 | literal、絶対命令を盛ると過剰追従 | literal、説明より examples が効く | broad な否定命令で over-index、肯定指示が安全 |
| プロンプト構造の推奨 | Goal / Success / Constraints / Output / Stop / Personality | 役割 + key facts + 例 + tool spec + budget | 具体的な肯定指示 + thinking レベル指定 + context 明示 |
| ツール定義 | tool description 側に I/O を寄せる | tool spec が「真の prompt」 | ネイティブ tool/function を優先 |
| 長文コンテキスト | 静的 prefix + 動的 suffix、cache hit を取りにいく | 重要事実は task の直前に再掲 | 関連 context を明示し「推測するな」より「使え」と書く |
| コスト戦略 | effort low から段階的に上げる、>272K input は価格倍率に注意 | task budget (beta) で agentic loop に上限 | 60% LOW / 30% MED / 10% HIGH ルーティング |
ベンダーごとのパラメータ名は違っても、「思考量はノブで渡す」「指示は薄く例で示す」「温度や絶対命令で殴らない」の三点が共通項として浮かび上がる。プロンプトエンジニアリングという職能は、3 つのフラグシップを跨いで同じ作法に収束しつつある。
後半:移行実践編 — GPT-5.5 への書き直し手順
ここからは思想ではなく作業の話だ。社内に残っている GPT-4 時代のプロンプトを gpt-5.5 に乗せ替えるとき、どこから手をつけ、どこまで削るかを順に書いていく。
ステップ 1:旧プロンプトを「不変条件」と「判断ルール」に分解する
最初にやるのは、いきなり書き換えることではなく、棚卸しだ。旧プロンプトの全行に対して次の 3 タグを付ける。
- 不変条件: 安全・法務・ブランド・スキーマなど、いかなる入力でも守らせたい線
- 判断ルール: 「こうなったらこうする」という条件付きの振る舞い
- 手順固定: 「N 回検索しろ」「必ず step-by-step に書け」など、解き方をモデルに強制している指示
GPT-5.5 の移行で真っ先に削るのは「手順固定」だ。process-heavy な指示を持ち込むほど、モデルは判断より儀式を優先するようになる12。
ステップ 2:5 ブロック契約テンプレートに書き直す
旧プロンプトを「契約」として書き直す基本形は次の通り。
Role:あなたは <ドメイン> の調査・実行アシスタント。根拠付きで仕事を完了する。
# Personality簡潔、落ち着いていて、実務的。必要なときだけ短く確認する。
# Goalユーザ要求を、使える成果物として完了する。
# Success criteria- ユーザの主要質問に答える- 重要な事実には根拠がある- 必要なアクションは、許可される範囲で実行済み- 根拠不足なら最小の不足情報だけを確認する
# Constraints- 不確実な点は断定しない- 不要な検索や不要なツール呼び出しはしない- 重要な事実は必ず引用する- 安全・法務・権限制約を超える行動はしない
# Output- 結論- 根拠- 実施したアクション- 未解決事項 / blockers
# Stop rules- 核心質問に必要十分な根拠で答えられたら止める- phrasing 改善のためだけに追加検索しない- 正確性に影響する不足情報があるときのみ、狭い確認質問をするこのテンプレートは OpenAI が GPT-5.5 で推奨する Goal / Success criteria / Constraints / Output / Stop rules、および短い personality / collaboration style 構造とそのまま対応している12。長く書く必要はなく、これだけで多くの旧プロンプトを置き換えられる。
ステップ 3:API 初期値を決める
実装側では、まずこの設定から始めるとよい。
{ "model": "gpt-5.5", "reasoning": { "effort": "low" }, "text": { "verbosity": "low" }}OpenAI 自身が、GPT-5.5 は同じ努力量でも prior model より効率的に考えられるとしており、多くの workload で low から十分機能すると述べている12。medium がモデルの default だが、すべての画面・全ユーザ操作で default を使う必要はない。UX 起点で surface ごとに以下の指針を持つと整理しやすい。
- 会話 UI、即応性が重要な箇所:
effort=low+verbosity=low - レポート生成、分析、長文要約:
effort=medium+verbosity=medium - 難しいコード生成、複数手段の照合、研究的タスク:
effort=high、必要なら非同期でxhigh temperatureは触らない: 旧癖でtemperature=0にする前に、まず effort と verbosity を動かす
ステップ 4:Before / After で実例を見る

社内によくある旧プロンプトと、GPT-5.5 向けの書き直しを並べる。
Before(GPT-4時代の典型)
You are a helpful assistant.ALWAYS think step by step.ALWAYS search at least three times before answering.NEVER stop until all possible sources are exhausted.You must explain your entire reasoning to the user.Today is 2026-05-15.Output exactly this JSON:{ "answer": "...", "sources": [...], "confidence": "...", "follow_up_questions": [...], ...20行ほど続くschema...}このプロンプトを GPT-5.5 にそのまま渡すと、毎回 3 回検索を回し、JSON フィールドを増やし、refusal が増え、出力が長くなり、reasoning token が context を食う。
After(GPT-5.5向け書き直し)
Role:あなたは根拠重視の実務アシスタント。
# Goalユーザの質問に、必要十分な根拠で答える。
# Success criteria- 核心質問に答える- 重要な事実に引用がある- 不足情報がある場合だけ最小の確認をする
# Constraints- 不要な検索はしない- 出力スキーマは Structured Outputs を使う- 不確実な点は断定しない
# Output結論、根拠、blockers
# Stop rules- 核心質問に答えられたら止める- phrasing 改善のためだけの追加検索はしない加えて API 側でやることはこうだ。
toolsフィールドに検索ツールを正しく定義し、tool description に「いつ呼ぶか、何を返すか、副作用はあるか」を集約する- JSON schema は prompt から消し、Structured Outputs /
response_formatに渡す - 「今日は2026年5月15日」のような日付は prompt から消し、必要なら developer message かツール経由で動的に渡す
previous_response_idを使い、reasoning persistence を活かす10- 長い prompt を使うなら、静的部分を前、動的部分を後に置き、cache hit を取りにいく
ここまでやって、ようやく「同じプロンプトを書き直した」ではなく「同じ要件を GPT-5.5 のために契約として書いた」に近づく。
ステップ 5:UX 側の手入れ
GPT-5.5 の default はやや事務的だ。素のままだと「冷たい」「無言で固まったように見える」と感じるユーザがいる。これは性能の問題ではなく、UX 設計の問題なので、プロンプト側で小さく補えば済む12。
- ツール呼び出しの前に、1〜2 文の 短い preamble を必須化する(「いま検索をかける」「いまファイルを読む」程度で十分)
Personalityブロックに 温度感 を、Collaboration styleブロックに 協働の作法 を分けて書く。トーンとタスク挙動を別ノブで持つと、後でどちらかだけ調整できる- 確認質問は「不足情報が結論を materially に変える場合だけ」とルール化する。何でも聞き返す体験は摩擦になる
- 完了報告は
completed_actions/customer_message/blockersのように分けると、人間の handoff が楽になる
長く書くより、短い節を 3〜4 個並べる方が、トーンも安定する。
ステップ 6:移行チェックリスト
最後に、実装担当が手元に置いておくと事故が減るチェックリストを置いておく。
- 旧プロンプトを「不変条件」「判断ルール」「手順固定」に三分し、手順固定はまず削る
-
systemに混ざっていた業務ロジックをdeveloperメッセージとツール定義に再配置する -
ALWAYS search N times/step by step/ 「絶対に〜」を Goal・Success・Stop rules に圧縮する - 出力 schema を prompt から外し、Structured Outputs /
response_formatに寄せる - multi-turn・tool use・reasoning を伴うケースは Responses API +
previous_response_idに移す -
reasoning.effortをlow→medium→highの順で評価し、xhighは難タスクと非同期用途に限定する - 既定の
text.verbosityを画面ごとに決める。チャット UI はlowから始める - 静的 prefix と動的 suffix を分け、cache hit を取りに行く
-
max_output_tokens設計時に reasoning token も課金・context を消費する ことを前提に余白を取る - tool-heavy workflow では preamble・phase 切り替え・assistant-item replay を実装する
- ローカル eval を「指示型 / 会話型 / ツール呼び出し / 長文要約 / 創作」の 5 類型で回す
- eval 指標を accuracy、adherence、generated tokens、end-to-end latency、failure cases の 5 軸で揃える
よくある事故と回避策
| 症状 | 原因の典型 | 回避策 |
|---|---|---|
| 回答が硬直、毎回同じ検索ループ | 旧プロンプトの「ALWAYS N times」が残っている | Stop rules と retrieval budget に圧縮 |
incomplete で答えが返らない | reasoning token が max_output_tokens を食い切った | effort を下げるか output 上限を上げる |
| JSON が崩れる、enum が増える | prompt 内の手書き schema を残している | Structured Outputs に完全移譲 |
| 長文の中央の指示が無視される | 1M context を埋めたが指示を先頭にしか置いていない | 先頭と末尾に再掲、delimiter を Markdown/XML 化 |
| UX が冷たく感じる | Personality と Collaboration style を書いていない | 短い 3 行ずつ追加、preamble 必須化 |
| 想定外の refusal | broad な禁止命令で over-index している | 否定指示を肯定指示に書き換える(Gemini 系で顕著だが GPT-5.5 でも有効) |
| benchmark は良いのに本番で悪い | OpenAI 公開値は xhigh の研究環境の数字 | 自社プロンプトで medium 相当の eval を必ず回す |
とくに GPT-5.5 では、reasoning token が見えないのに billing と context を食う、272K を超える入力は session 単位で価格倍率がかかる、phase / replay 実装を誤ると長い workflow で一貫性が崩れる、の 3 点が技術チームに見落とされやすい12。
まとめ:プロンプトを書く仕事は、契約を書く仕事になった
GPT-3.5 から GPT-5.5 までの公式ガイドを並べると、こう要約できる。
- GPT-3.5 / 4: モデルを誘導するための 指示文
- GPT-4o / 4.1: モデルと API を整列させるための 構造化
- GPT-5 / 5.5: モデルに渡す 運用契約
Anthropic Opus 4.7 と Gemini 3 Pro の最新ガイドも、語彙の違いを超えて同じ三本柱(思考量はノブで渡す、指示は薄く例で示す、温度や絶対命令で殴らない)に揃った12。フラグシップを横並びで見たとき、プロンプトエンジニアリングはもう「呪文を書く仕事」ではなく、 業務委託のスコープを書く仕事 に近い。
移行時に意識すべき点はひとつに集約できる。
旧プロンプトを「足す」のではなく、「契約として書き直す」。
短い Goal、明確な Success criteria、現実的な Constraints、納品様式としての Output、引き渡し条件としての Stop rules。これらを書いたら、あとはモデルに任せる。公式ガイドが繰り返し示している設計はこの構造だった。
参考資料
Footnotes
Anthropic, “Prompting best practices” (Claude API Docs) — Claude 系全モデルの最新リファレンス。examples 優先、tool definition を prompt の核として扱う方針。 ↩ ↩2 ↩3 ↩4
Google Cloud Documentation, “Gemini 3 prompting guide” —
temperature=1.0の維持推奨、broad な否定命令 (“do not infer/guess”) の弊害、肯定指示への書き換え、low + “think silently” によるレイテンシ短縮、コンテキストの明示。 ↩ ↩2 ↩3 ↩4OpenAI Cookbook (archived), “How to format inputs to ChatGPT models” — system/user/assistant の役割と、
gpt-3.5-turbo-0301での system 追従の弱さ、重要指示の user 側への再掲推奨について記載されている。 ↩OpenAI, “GPT-4” release notes, 2023 — GPT-3.5 比で人手評価 prompt 70.2% 好まれた点、複雑指示・ニュアンス理解の改善、hallucination 回避率の差分 (open-domain +19pt, closed-domain +29pt) を提示。 ↩
OpenAI, “Hello GPT-4o” — GPT-4 Turbo 級性能を低コスト・低レイテンシで提供、音声応答最短 232ms、平均 320ms、provider 経由 text TTFT 0.96s, 136.8 tokens/s の参照。 ↩
OpenAI API Docs, “Structured Outputs” /
response_format— JSON schema 強制を prompt から API に移すための機能。schema adherence と refusal 検出を API 側で扱える。 ↩OpenAI Cookbook, “GPT-4.1 Prompting Guide” — literal な指示遵守、
toolsフィールド経由のネイティブ tool 利用が手書き schema より SWE-bench Verified を約 2% 向上、planning 明示で pass rate 約 4% 改善、長文 prompt では指示を先頭と末尾に置き、JSON より Markdown/XML を推奨。 ↩OpenAI, “Introducing GPT-4.1” — extraneous edits が GPT-4o の 9% から GPT-4.1 の 2% へ低下、Video-MME 長尺なし字幕 72.0、MultiChallenge 38.3、IFEval 87.4 など。 ↩
OpenAI API Docs, “Using GPT-5” / “Reasoning models” —
reasoning.effort、text.verbosity、developerrole の導入、tool preamble、eagerness 制御、CoT を prompt 側で強制せず goal/constraints/output で渡す方針。 ↩OpenAI Cookbook, “GPT-5 New Params and Tools” / “Reasoning persistence with Responses API” — Responses API 採用だけで SWE-bench 3% 改善、
previous_response_idで Tau-Bench Retail が 73.9% から 78.2% に改善した報告。 ↩ ↩2Wei et al., “Chain-of-Thought Prompting Elicits Reasoning in Large Language Models” — 大規模モデルに対する中間推論外部化が複雑推論を改善する古典結果。GPT-4.1 までは prompt 側 CoT が有効、GPT-5 系では reasoning model 内部に任せる方向に移行している背景。 ↩
OpenAI API Docs, “Using GPT-5.5” / “Prompt migration guide” — GPT-5.5 の baseline 書き直し方針、Goal/Success/Constraints/Output/Stop rules + Personality/Collaboration style 構造、
reasoning.effort=mediumを default としつつlowから始める実務指針、text.verbosity=lowの挙動、Tau2-bench Telecom 98.0、SWE-Bench Pro 58.6、Terminal-Bench 2.0 82.7、OSWorld-Verified 78.7、MRCR v2 (512K-1M) 74.0、272K 超入力での価格倍率、reasoning token が課金と context を消費する点。 ↩ ↩2 ↩3 ↩4 ↩5 ↩6Linas Substack, “Claude Opus 4.7: The Complete Prompting Playbook (2026)” など複数の Opus 4.7 移行解説 — literal な指示遵守、effort パラメータ、500K トークン prompt の中央詳細の取りこぼし対策、
max_tokensを 20〜35% 増しに、task budget (beta) で agentic loop に上限を設ける手法。 ↩ ↩2Google Cloud / Firebase AI Logic / LaoZhang AI Blog の Gemini 3.1 Pro thinking levels 解説 —
thinking_level(LOW/MEDIUM/HIGH) の明示推奨、API default がHIGHでコストが膨らみがちな点、60% LOW / 30% MED / 10% HIGH ルーティングで月次 thinking token コストを 70〜75% 圧縮できるという推奨。 ↩ ↩2