
Qwen3.6-27B がアツい:27B dense でClaude 4.5 Opus に肉薄したオープンウェイトの転換点
はじめに
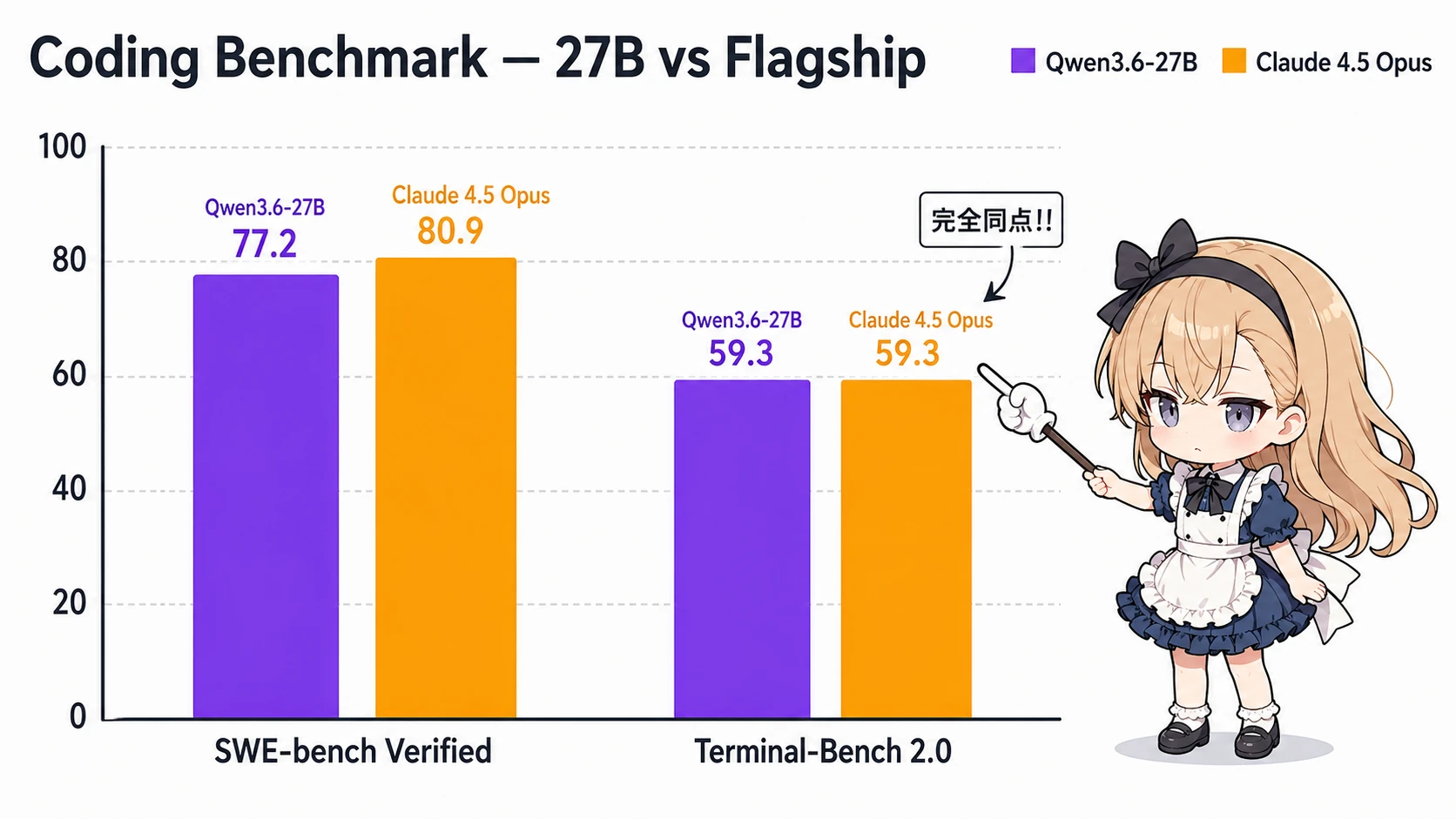
2026年4月22日、Alibaba Qwen チームが Qwen3.6-27B をリリースしました1。Apache 2.0 ライセンスの dense 27B モデルで、SWE-bench Verified 77.2、Terminal-Bench 2.0 59.3 という、クローズドフラッグシップ級のコーディングスコアを叩き出しています2。
この数字、何がアツいのか。Claude 4.5 Opus との差が SWE-bench Verified で 3.7pt、Terminal-Bench 2.0 では完全同点 になっているからです。フロンティアモデルへ毎月課金していた開発者にとって、「ローカル実行に逃げる」選択肢が一気に現実味を帯びました。
しかも、前世代フラッグシップだった Qwen3.5-397B-A17B(MoE、HuggingFace 上 807GB)に対して、Qwen3.6-27B は 55.6GB。14.8 倍小さくなった上で、主要な agentic コーディングベンチを上回っています3。
本記事では、この「27B でここまで来た」リリースの何がどうアツいのかを、5 つの切り口で整理します。
2026-06-07 追記:手元の M5 Pro 48GB MacBook Pro + ollama で実測した速度・メモリ・品質(テストによる機械判定)のデータを「実測」セクションに追加しました。

ココがアツい① 27B dense でクローズドフラッグシップに肉薄
まずはベンチマーク。Qwen 公式が出した数字を Claude 4.5 Opus と並べると、コーディング系の差が驚くほど詰まっています。
| ベンチマーク | Qwen3.6-27B | Claude 4.5 Opus | 差分 |
|---|---|---|---|
| SWE-bench Verified | 77.2 | 80.9 | -3.7pt |
| Terminal-Bench 2.0 | 59.3 | 59.3 | ±0 |
| SWE-bench Pro | 53.5 | - | - |
| SkillsBench | 48.2 | - | - |
特に Terminal-Bench 2.0 で完全同点になったのが象徴的です2。これはターミナル環境でのコマンド実行・ファイル操作を含む agentic ベンチで、実務に近いタスク群で評価されます。「クローズドの Opus と並んだ」と言える唯一のオープンウェイトモデルが、ついに 27B サイズで出てきた ことになります。
SWE-bench Verified の 77.2 という数字も、半年前なら 200B 超のクローズドモデルでなければ届かなかった水準です。Apache 2.0 で重みが落とせる以上、社内データで Fine-tune するハードルも一気に下がります。
ココがアツい② 14.8倍コンパクトで前世代の397B MoE を超える
次にアツいのが、前世代の Qwen3.5-397B-A17B(MoE)を 27B dense が抜いた という事実です。
| ベンチマーク | Qwen3.5-397B-A17B (MoE) | Qwen3.6-27B (dense) | 改善幅 |
|---|---|---|---|
| SWE-bench Verified | 76.2 | 77.2 | +1.0pt |
| Terminal-Bench 2.0 | 52.5 | 59.3 | +6.8pt |
| SWE-bench Pro | 50.9 | 53.5 | +2.6pt |
| SkillsBench | 30.0 | 48.2 | +18.2pt(+60%) |
| HuggingFace サイズ | 807GB | 55.6GB | 1/14.5(-93.1%) |
SkillsBench の +18.2pt(相対 +60%)が特に異常な伸びで、Qwen チームは「ベンチ最適化ではなく、コミュニティからの実運用フィードバックを優先して設計した」と明言しています3。
つまり、業界の流れだった 「MoE で総パラメータを盛る」路線から、「dense + ハイブリッドアテンション + Multi-Token Prediction」路線への転換 が成功事例として提示された格好になります。スパース化で運用コストを上げる前に、設計レベルで効率を取りに行く、という選択肢が現実的なものとして見え始めました。
ココがアツい③ 量子化16.8GBでローカル実行——API課金から逃げられる
3 つ目は実装側のアツさ。Q4_K_M 量子化版なら 16.8GB まで縮みます4。これは、24GB クラスの消費者向け GPU や、64GB 統合メモリの Mac で動かせるサイズです。
Simon Willison がリリース当日に M 系 Mac + llama-server で動かしたレポートでは、生成速度が 約 25 tokens/s、読み込みが 54.32 tokens/s と報告されています4。SVG 生成のような視覚的タスクでも「flagship 級の出力品質」と評価しており、量子化後の品質劣化も実用範囲に収まっているようです。
対応する推論スタックも幅広いです。
- llama.cpp:GGUF 提供あり、
llama-serverで Jinja テンプレート対応 - vLLM / SGLang / KTransformers:本格運用向けの推論サーバ
- LM Studio:公式モデルカタログから 1 クリック導入
- Hugging Face:BF16 版・FP8 版(fine-grained FP8、block size 128)の 2 種類が同時公開5
API レート制限やベンダーロックを避けたいチーム、機密コードを外部に投げたくない組織にとって、「とりあえずローカルで Opus 級が動く」状態が Apache 2.0 で手に入った のは決定的な転換点なん(と書きたくなるレベル)です。

【実測】M5 Pro 48GB の MacBook Pro で動かしてみた(2026-06-07 追記)
ここまで Simon Willison の報告を引用してきましたが、後述の注意点で「自分のユースケースで触って確認するしかない」と書いた以上、自分でも測りました。手元の MacBook Pro(Apple M5 Pro、統合メモリ 48GB)+ ollama 0.30.6 で qwen3.6:27b(Q4_K_M 量子化、17GB)を実行した一次データです。
メモリと速度:48GB なら余裕、生成は約 15 tokens/s
| 項目 | 実測値 |
|---|---|
| メモリ占有 | 18GB(100% GPU 実行、swap なし) |
| モデルロード | 6.0 秒 |
| 生成速度 | 14.7〜15.2 tokens/s(4 回計測、短〜中文脈で安定) |
| 入力処理速度 | 365 tokens/s(6,714 トークンの実コードを 18.4 秒で読了) |
生成は安定して約 15 tokens/s でした。Willison の報告(約 25 tokens/s)より遅いのは、M5 Pro のメモリ帯域が Max 系チップの約半分だからで、想定内です。むしろ収穫だったのは入力処理の速さで、手元の 23.6KB の Astro コンポーネント(約 6,700 トークン)を 18 秒で読み切ります。コードレビューや要約のような「長い入力 → 短い出力」タスクとの相性は良好です。
品質:テストで機械判定したら一発合格だった
「Opus 級」をどう検証するか。主観を排するため、先にテストを書いてからモデルに実装させ、生成コードを無修正のまま bun test にかけました。
- debounce 実装(leading / trailing オプション + cancel メソッド、テスト 7 本)→ 7/7 一発合格
- 非同期バグ修正(missing await で rejection が try/catch を素通りする retry 関数、テスト 4 本)→ 4/4 一発合格。バグ原因の説明も一文で正確でした
(2) の missing await は型チェックでは捕まらず、人間のレビューでも見落としやすい類のバグですが、迷いなく特定して return await fn() に修正してきました。2 タスクの小規模検証という前提つきですが、ローカル 27B の出力としては文句なしです。
ただし thinking が長い:関数 1 個に 7 分待つ
正直に書くべきはここです。Qwen3.6-27B はデフォルトで thinking(推論トレース)が有効で、これが体感を支配します。
- 一文で答えられる質問に 331 トークン思考
- Python 関数 1 個の生成に 6,019 トークン、6 分 50 秒
- 上記 debounce 実装には 11,086 トークン、12.8 分(思考が長引くとコンテキストが伸び、生成速度自体も 8.4 tokens/s まで低下)
品質はこの思考量に支えられているので、単純に「無駄」とは言えません。ただ、ペアプロのような対話的な使い方には向かず、「タスクを投げて別作業をして戻ってくる」非同期運用が前提 になります。API の think: false で思考を切れば応答は数十秒に縮みますが、上記の品質がどこまで維持されるかは別途検証が必要です。
まとめると——48GB の M 系 Mac で「Opus 級の品質」は本物。ただし「Opus 級の応答速度」ではありません。 これが実測の結論です。
ココがアツい④ Thinking Preservation で長期エージェントが回る
4 つ目は agentic 用途で効くアツさ。Qwen3.6-27B は オープンソース初の Thinking Preservation を搭載しています3。
これは、マルチターンのエージェントループで途中の reasoning trace(思考履歴)を破棄せずに保持する仕組みです。20 ステップを超えるような自律実行でも、初期の前提や制約条件を見失いにくくなります。
具体的なメリットが出るのは以下のような場面です。
- Cline / Roo Code / OpenHands のような長時間ループ系コーディングエージェントとの組み合わせ
- リポジトリ全体を読んで段階的にリファクタを進めるタスク
- 仕様書 → 設計 → 実装 → テストを 1 ループで完結させる開発フロー
これまでオープンウェイトモデルは「短いタスクなら強い、長期ループだと前提を忘れる」と言われがちでしたが、Thinking Preservation はその弱点を直接突いた機能追加です。
ココがアツい⑤ アーキテクチャ自体が新しい
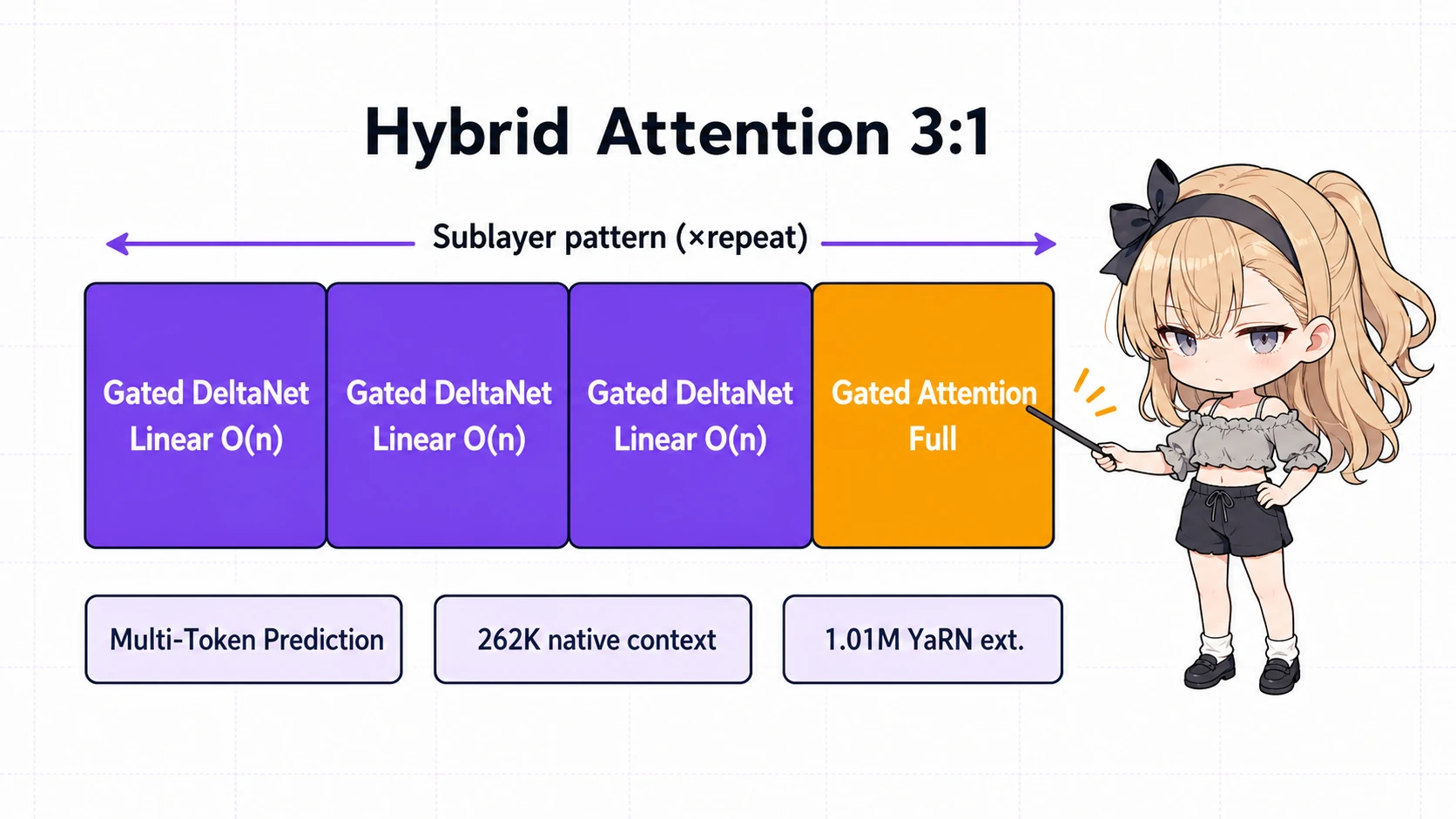
最後は技術的なアツさ。Qwen3.6-27B のアーキテクチャはハイブリッド構成で、サブレイヤーの 3/4 を Gated DeltaNet(線形アテンション、O(n) 計算量)、残り 1/4 を従来型 Gated Attention に振り分けています3。
これにより以下が同時に成立します。
- 長文脈での KV キャッシュ消費を抑える:262K ネイティブコンテキスト、YaRN 拡張で 1,010,000 トークン までスケール
- Multi-Token Prediction を内蔵:speculative decoding を別ドラフトモデルなしで有効化できる
- マルチモーダル入力:テキストに加えて画像・動画もネイティブで処理(UI スクリーンショットからの実装起こしや、図解付き仕様の取り込みが 1 モデルで完結)
「線形アテンションは品質が落ちるからフルアテンションで」という従来の常識を、比率を 3:1 に振ってベンチで殴る スタイルで覆しに来た構成です。1M トークンの実用コンテキストを持つオープンウェイトモデルが、消費者 GPU で動く規模で出た意味は大きいです。
注意点:手放しで称賛できない部分
ここまでアツさを語ってきましたが、冷静に見るべき点もあります。
ベンチ評価の前提:Qwen が報告したスコアは、Qwen 内製の agent scaffold(bash + file-edit ツール群)込みの数値です。2026年4月23日時点で、第三者の独立再現はまだ限定的だと報じられています6。導入前には、自社のスキャフォールドや MCP 経由のエージェント構成で再評価する前提で読むべきです。
実機検証の範囲:Simon Willison の手元検証はSVG生成や軽い推論タスクが中心で、リポジトリ規模の agentic コーディングタスクを大規模に検証したものではありません4。本記事の実測セクションでテスト判定による品質確認を一段進めましたが、それでも 2 タスクの小規模検証です。「Opus 級の品質が量子化後にも保たれるか」は、最終的には自分のユースケースで触って確認するしかありません。
ライセンスと運用:Apache 2.0 は商用利用可ですが、生成物の責任は利用側に残ります。社内で本番投入する際は、出力監査やフォールバック先(Claude / GPT API)の設計を併用するのが堅実です。
開発者として、いま試したい 3 つの使い方
「アツい」を体感したい人向けに、すぐに試せる導入パターンを 3 つ。
- LM Studio + Cline で agentic コーディング:LM Studio で
qwen/qwen3.6-27bを 1 クリック導入し、Cline の API エンドポイントをlocalhostに向けるだけ。Apache 2.0 の Opus 級が手元で回ります。 - vLLM 立てて社内コードレビュー:FP8 版を vLLM に乗せれば、Hopper 系 GPU 1 枚で 1M コンテキストの社内コードレビュー Bot が組めます。GitHub 連携部分だけ追加すれば PR レビュー自動化が現実的に。
- マルチモーダルで UI → コード:スクリーンショットを投げて React/Tailwind 実装を出させる用途。UI スナップショットからの実装起こしが、外部 API なしでローカル完結できる時代になりました。
「ローカル27Bが API に勝つ」のはどこからか
このリリースの意義は、ベンチの点数そのものより「ローカル実行が現実的な選択肢になった」ことにあります。ただし「動く」と「API より得」は別の話です。冷静に損益分岐を引くと、ローカル27Bが API を上回るのは、次の条件が重なったときに絞られます。
- プライバシー要件が固い:コードや顧客データを外部 API に出せません。ここはコスト計算以前に、ローカル一択になります。
- 常時・高頻度に回す:GPU の固定費を、API の従量課金が上回るだけの稼働量があります。月数十リクエスト程度なら API のほうが安いです。
- レイテンシと可用性を自分で握りたい:外部 API のレート制限や障害に左右されたくありません。
逆に、たまにしか使わない/最高品質が要る/運用に人員を割けないなら、素直にクローズド API を使うほうが総コストは低くなります。「オープンウェイトがフラグシップに肉薄した」のは事実ですが、それは「全員がローカルに移行すべき」を意味しません。 肉薄したのは性能であって、運用コストではありません。 Qwen3.6-27B が変えたのは選択肢の幅であり、最適解は依然としてワークロード次第です。
まとめ
Qwen3.6-27B のアツいポイントを整理します。
性能のアツさ:
- SWE-bench Verified 77.2、Terminal-Bench 2.0 で Claude 4.5 Opus と同点
- 14.8 倍小さい dense 27B が前世代 397B MoE を主要ベンチで上回る
- SkillsBench で +18.2pt(相対 +60%)の異常な改善幅
実装のアツさ:
- Q4_K_M 量子化版で 16.8GB、消費者 GPU・統合メモリ Mac でも動く
- llama.cpp / vLLM / SGLang / KTransformers / LM Studio に即対応
- BF16 / FP8 の両重みが Hugging Face に同時公開
アーキのアツさ:
- Gated DeltaNet × Gated Attention の 3:1 ハイブリッド構成
- Multi-Token Prediction 内蔵で speculative decoding 単独運用
- 262K ネイティブ / 1M YaRN コンテキスト + マルチモーダル入力
実測のアツさ(M5 Pro 48GB、2026-06-07):
- メモリ占有 18GB・swap なし、生成は約 15 tokens/s で安定
- テスト先行の品質判定で debounce 実装 7/7・バグ修正 4/4 の一発合格
- ただし thinking デフォルトで関数 1 個に 7〜13 分——非同期運用が前提
注意点:
- ベンチは Qwen 内製スキャフォールド込み、第三者再現は限定的
- 実機検証で自社ユースケースを必ず確認
「クローズドフラッグシップとオープンウェイトの差」を語る基準が、このリリースで明確に書き換わりました。少なくとも 「コーディング用途で Apache 2.0 のローカルモデルを試す価値」が、いままでで最大になった のは間違いありません。週末に手元で動かして、Opus との差を自分の目で確かめる絶好のタイミングです。
参考文献
Footnotes
Qwen3.6-27B: Flagship-Level Coding in a 27B Dense Model - Qwen Blog ↩
Qwen3.6-27B: 27B Model Beats 397B on Coding (2026) - Build Fast with AI ↩ ↩2
Alibaba Qwen Team Releases Qwen3.6-27B - MarkTechPost ↩ ↩2 ↩3 ↩4
Qwen3.6-27B: Flagship-Level Coding in a 27B Dense Model - Simon Willison ↩ ↩2 ↩3
Qwen3.6-27B VRAM Requirements — Dense 27B That Beats 397B-A17B - Will It Run AI ↩