
RAG を作る前に読む地図 — 用語が「どこで牙を剥くか」を先に押さえる
「ChatGPT に社内ドキュメントを参照させたい」「自社の FAQ から正確に答えてほしい」。この要望にもっともよく当てはまる手法が RAG (Retrieval-Augmented Generation) で、検索すれば「RAG 入門」記事は無数に出てきます。けれど、ほとんどは「動くサンプル」で止まります。そして用語のほうも、embedding や reranker や Faithfulness を 定義だけ 覚えても、いざ自分で作り始めると「で、これは結局どこで効くの?」と剥がれ落ちていきます。
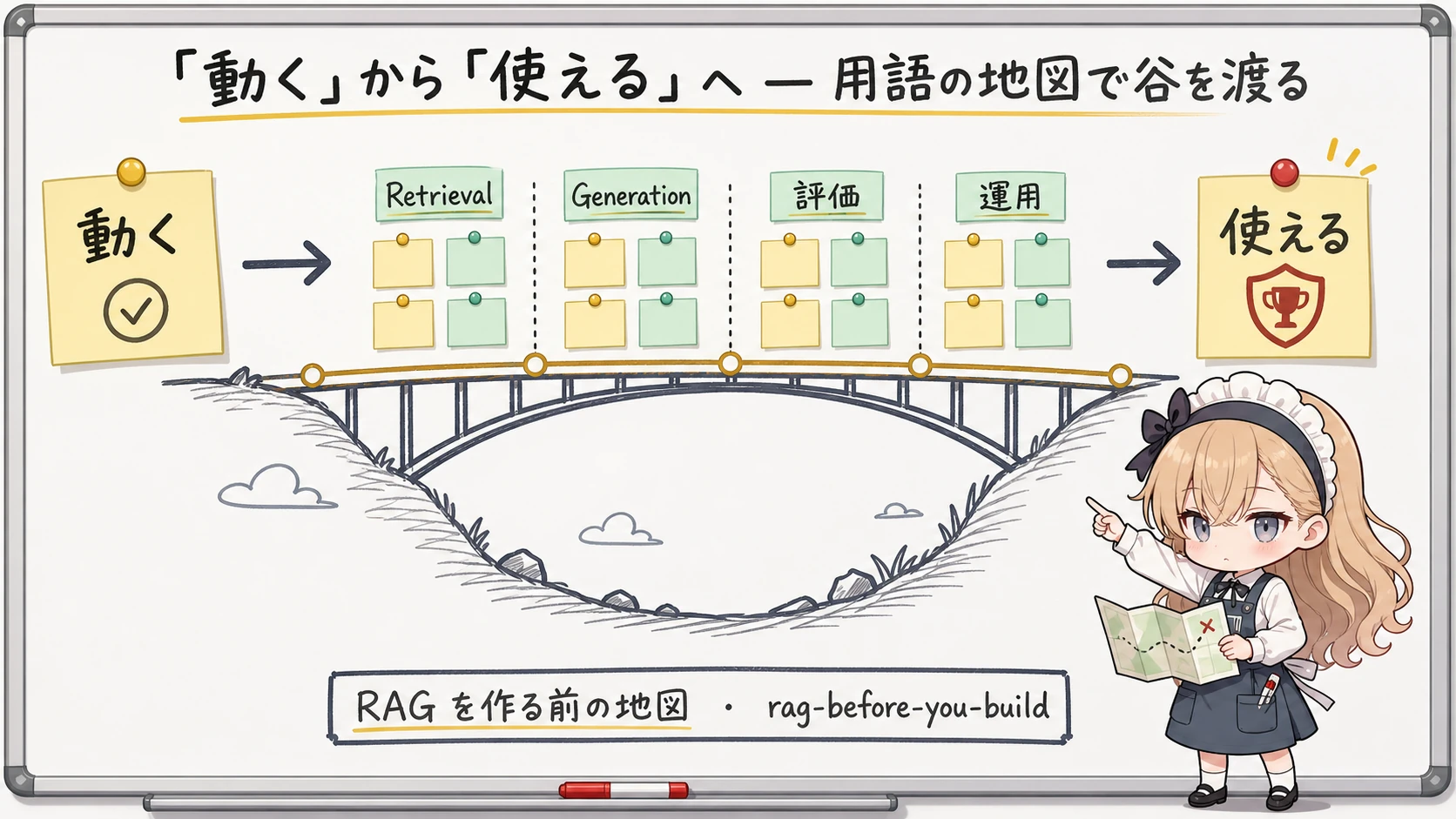
この記事は、もう一本の「RAG とは」用語集ではありません。配るのは 「用語 → それが本編のどの工程で、どんな失敗として牙を剥くか」の地図 です。題材にするのは、このブログの連載「今更聞けない RAG の作り方、評価の仕方」全 5 部。各 Part で実際に手を動かして観察した失敗に、用語を 1 つずつ貼り付けていきます。読み終わったとき、本編のどの回が自分の課題を解くのかを、自分の言葉で選べるようになっているはずです。
RAG とは「LLM にカンペを渡す」こと — 何で、何でないか
一言で言えば、RAG は 検索 (retrieval) を組み合わせて、生成 (generation) を補強する 手法群の総称です。LLM に質問をそのまま投げるのではなく、関連しそうな文書を先に 探してきて (retrieval)、それをカンペとして渡してから 答えさせる (generation)。用語の原典は Lewis らの論文 (2020)[^1] で、いまでは「LLM が訓練時に知らなかった外部知識を、推論時に context として差し込む」汎用パターンの総称として使われます。実装の素朴さの度合いで Naive / Advanced / Modular と分類され[^2]、本編 Part 1 はもっとも素朴な Naive RAG から始めます。
大事なのは、RAG が 万能ではない ことです。RAG が向くのは「答えに事実が必要で、その事実が学習データに含まれていない、または古い」タスク——社内 wiki、製品 FAQ、技術文書のように 更新頻度が高くドメイン特異 な知識です。逆に、創作 (小説・コピー) のように事実より文体が主役のタスク、軽量モデルで足りる分類タスク、1 秒以内の応答が要るリアルタイム用途には向きません (embedding と retrieval と LLM 呼び出しで数百 ms 〜 数秒かかるからです)。判断軸は 「変更頻度 × 正確性要求」をかけたとき、fine-tuning より RAG が割に合うか。毎週変わる社内 wiki なら RAG、年単位のブランドガイドラインなら fine-tuning でも良い、という具合です。
なぜ「用語集」ではなく「地図」なのか
用語の定義を 1 行ずつ並べた表は、読んだ直後はわかった気になります。けれど 使う場面と結びついていない知識は、手を動かし始めた瞬間に剥がれます。cosine 類似度 が何かを言えても、「なぜ語が一致しているのに間違った文書が上位に来るのか」を経験していなければ、その対策 (reranker) の必要性は腹落ちしません。
そこでこの地図は、用語を 本編 5 部の 4 つの工程 に貼り付けて並べます。Retrieval (Part 2)、Generation (Part 3)、評価 (Part 4)、運用 (Part 5)。各工程で、その用語が どんな失敗として牙を剥くか をセットにします。だから入門記事でありながら、同時に「自分はどの回から読むべきか」を選ぶ目次にもなっています。
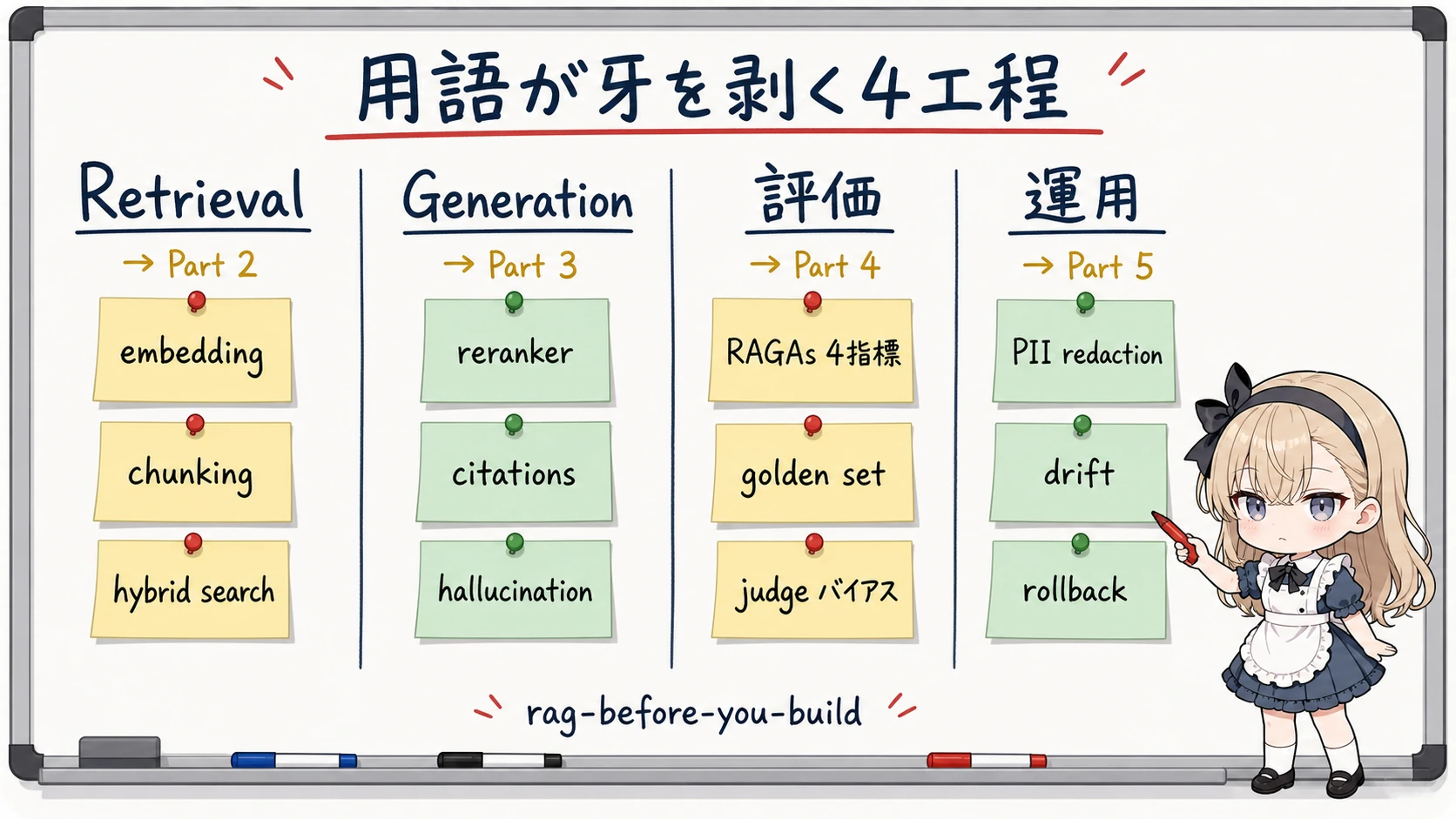
工程 1 Retrieval — embedding・chunking・hybrid が「取りこぼし」で牙を剥く
最初の工程は カンペを探す 部分です。ここで登場する用語が、本編 Part 2 でこう牙を剥きます。
- embedding (ベクトル化): 文を「意味の座標」——数百次元の数値の並びに変換する操作です。近い意味の文はベクトルも近くなる、というのが狙いです。ところが固定長で切った chunk を 1 つの embedding モデルだけで表すと、言い回しの違う同義語を 取りこぼします。原因は、文埋め込みが意味だけでなく表層の構文にも引っ張られる性質です[^3]。
- cosine 類似度 / top-K: ベクトル同士の近さ (cosine) で上位 K 件を取る、retrieval の心臓部です。これだけに頼ると、「ランニング部の練習計画」や「物流倉庫のロールバック」のように 語は一致するが意味は別物 の文書が top-5 に紛れ込みます。
- chunking: 文書を検索単位に切る作業です。素朴に固定長で切ると、見出しや「これは旧版 (archived) です」といった メタ情報が消えます。Part 2 では見出しを保持する splitter で chunk に版・状態を持たせ[^4]、
status filterで旧版を top-5 から追い出します。 - hybrid search (BM25 + dense): 意味の近さ (dense) だけでなく、語彙の一致 (BM25) も併用する方式です[^6]。スコアそのものは合成できませんが、ランクなら合成できる (RRF, k=60)[^5] という発想で両者を束ねます。
Part 2 のゴールは「chunking と hybrid で recall が数値で改善する」こと。ただし——意味的に近い trap は順位が下がらない、という 天井 が残ります。それを崩すのが次の工程です。
→ 詳しくは Part 2: Retrieval を真面目に。
工程 2 Generation — reranker・citations が「trap と根拠」で牙を剥く
次は カンペを見て書く 工程ですが、その前に「どのカンペを最終的に渡すか」を精密に選び直します。
- reranker / cross-encoder: query と文書を 同時に モデルへ入れて関連度を測り、並べ替える手法です。cosine を使う bi-encoder は query と文書を別々にベクトル化するため相互作用を見られませんが、cross-encoder は両者を突き合わせます[^7]。本編では top-20 を top-3 まで絞り、Part 2 で残った semantic trap の順位を 2 位から 9 位へ 落とします。
- 多言語 reranker: ただし reranker は モデル選択で結果が逆転 します。英語専用の reranker は日本語で精度が出ず、
bge-reranker-v2-m3のような多言語モデルが要ります[^8]。「とりあえず有名な reranker」を選ぶと、かえって悪化することがあります。 - grounding / citations: 回答を「どの文書のどこ」に紐付ける仕組みです。本編では Anthropic Citations API で
doc_id付きの根拠を返させます[^9]。ここでも「動く citation」と「使える citation」は別物で、根拠の引用が正しくても主張が正しいとは限りません。 - hallucination: 根拠のない、あるいは誤った生成のことです。purpose-built の法務 RAG でさえ 17〜34% が hallucinate するという報告があり[^10]、「引用を付けたから安心」とはなりません。だからこそ次の工程 (評価) で 数値にして 確かめます。
→ 詳しくは Part 3: Generation を引用付きで書く。
工程 3 評価 — RAGAs 指標と judge バイアスが「測り方」で牙を剥く
ここが連載のクライマックスです。「よくなった気がする」を 客観的な数値 に翻訳する工程で、ここを飛ばすと改善が思い込みのままになります。
まず、検索の良さと生成の良さは 別々に測ります (retrieval / generation / end-to-end の 3 層)[^11]。代表的なツール RAGAs の 4 指標を押さえておくと、本編がぐっと読みやすくなります。
- Faithfulness: 回答の各主張が、渡した context に裏付けられているか[^12]。hallucination の数値版です。
- Answer Relevance: 回答が質問にちゃんと対応しているか。
- Context Precision: 取ってきた文書のうち、本当に有用だった割合。
- Context Recall: 答えに必要な事実を、取ってきた文書がカバーできていたか。
評価には正解集合 (golden set) が要りますが、本編では 30 件で「十分」のラインに落ち着きます[^15]。そして最大の落とし穴が judge バイアス です。回答を生成するモデルと、それを採点する judge が同じだと、自分の答えを甘く採点する self-preference が避けられません[^13][^14]。本編では「英語 reranker が日本語スコアを下げていた」失敗を、まさにこの測定が炙り出します。何を測ってはいけないか を区別できて、はじめて評価になります。
→ 詳しくは Part 4: 評価 (クライマックス)。
工程 4 運用 — PII・drift・rollback が「本番」で牙を剥く
最後は、offline で良かったものが online で壊れる工程です。
- logging safety / PII redaction: 検索でヒットした chunk を default のままログに残すと、個人情報がそのまま蓄積され、重大インシデントになります。本編では取得・保存・出力の 3 箇所で redact します[^16][^17]。
- embedding drift: コーパスを更新し続けると、ベクトルの分布が少しずつずれていきます。検出と re-index のタイミングを設計しないと、ある日静かに精度が落ちます。
- rollback / incident playbook: 壊れたときに前の状態へ戻す手順です。本編では fault model を 4 つに分け、5 ステップの playbook を用意します。
- OpenTelemetry: 観測を
gen_ai.*という標準 attribute に乗せ、特定の監視 backend に縛られないようにします[^18]。
→ 詳しくは Part 5: 本番運用。
試すなら完全ローカルで — ただし「無料 ≠ 高速」
本編は API キーを 1 つも用意せずに、手元で完全に再現できます。LLM も埋め込みも Ollama に載せたローカルモデル (qwen3:8b と qwen3-embedding:0.6b) で動き、ollama pull だけで同じ数字を再現できます[^19]。
ただし、ここで 1 つだけ誤解を解いておきます。「無料 (0 円)」と「高速」は別物 です。単発のクエリは数秒で返りますが、Part 4 の一括評価 (30 件 × 3 パイプライン) は Apple Silicon でも 1 時間強 かかります。ローカル LLM では一括バッチが律速になるからです。「ローカルだから気軽」と「ローカルだから速い」は違う、と最初に知っておくと、評価の回で待ち時間に面食らわずに済みます。
ここから本編へ
地図を手にしたら、あとは順番に手を動かすだけです。まずは Part 1: 素朴な RAG の限界 で 100 行強の RAG を組み、「動く」と「使える」の谷を自分の目で見てください。そこから Retrieval (Part 2)、Generation (Part 3)、評価 (Part 4)、運用 (Part 5) と、この地図のとおりに進みます。
なお fine-tuning・multimodal RAG・agentic RAG は、本連載のスコープ外です。これらは Part 5 の末尾で「次の入口」として触れられています。まずは素朴な 1 本を、評価できて、運用できる 1 本に育てる——その道のりの地図として、この記事を使ってもらえればと思います。
参考文献
[^1]: Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks — Lewis et al., NeurIPS 2020. RAG という用語の原典
[^2]: Retrieval-Augmented Generation for Large Language Models: A Survey — Gao et al., 2023. Naive / Advanced / Modular RAG の分類
[^3]: Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks — Reimers & Gurevych, EMNLP 2019. embedding の表層構文 bias
[^4]: Markdown header metadata splitter — LangChain — heading 階層を chunk metadata に伝搬する production パターン
[^5]: Reciprocal Rank Fusion outperforms Condorcet and Individual Rank Learning Methods — Cormack et al., SIGIR 2009. RRF (k=60)
[^6]: The Probabilistic Relevance Framework: BM25 and Beyond — Robertson & Zaragoza. BM25 と同義語問題
[^7]: Retrieve & Re-Rank — sentence-transformers — cross-encoder の cross-attention と 2 段 pipeline
[^8]: BAAI/bge-reranker-v2-m3 — 多言語 cross-encoder reranker (日本語対応)
[^9]: Citations — Claude API Docs — grounding / cited_text 設計
[^10]: Hallucination-Free? Assessing the Reliability of Leading AI Legal Research Tools — Stanford 2025. purpose-built RAG でも 17-34% hallucinate
[^11]: Ragas: Automated Evaluation of Retrieval Augmented Generation — Es et al., EACL 2024. retrieval / generation / E2E の 3 層分離
[^12]: Faithfulness — Ragas — claim 分解 → context 内 evidence 検証
[^13]: Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena — Zheng et al., NeurIPS 2023. judge バイアス (position / verbosity / self-preference)
[^14]: Self-Preference Bias in LLM-as-a-Judge — 2024. gen=judge 同型時の self-preference
[^15]: RAG Evaluation: Metrics, Frameworks & Testing (2026) — golden 30-100 件が「十分」のライン
[^16]: RAG Pipeline Security Best Practices for 2026 — retrieved chunks ログのリスクと 3 箇所 redact
[^17]: Microsoft Presidio — PII detection / anonymization SDK
[^18]: OpenTelemetry semantic conventions for GenAI — gen_ai.* attribute 標準
[^19]: Qwen3 Embedding — qwen3-embedding ファミリ (本編のローカル既定経路)