
評価 (クライマックス) — RAGAs 4 指標で Part 1-3 の改善を客観評価する
2026-05-24 改訂: 本シリーズは Ollama + Qwen3 で完全ローカル再現できる構成に作り直しました。本記事のスコアはすべて judge =
qwen3:8b(Ollama) で実測した 30 件 × 4 指標です。generation も judge も同じqwen3:8bなので self-preference バイアスが構造的に乗ります — 絶対値ではなく Part 間の delta を信号として 読んでください。なお 30 件 × 3 pipeline の一括評価は Apple Silicon で 1 時間強かかります (Part 5 のコスト節で触れます)。
Part 1 で「動くけど使えない」失敗を 3 グループに整理し、Part 2 で hybrid+filter により旧版 (archived) を top-5 から追い出し、Part 3 で cross-encoder reranker と Anthropic Citations API で意味的 trap と引用喪失を縮めました。けれどここまでの「よくなった」はすべて 代表クエリ数件の眺め であって、客観評価ではありません。本記事 (Part 4) ではシリーズの宿題を回収します。30 件の golden set × RAGAs 4 指標 で、Part 1-3 の改善を 1 枚の表に翻訳します。
現在地 — フェーズ 3「測る」(連載の背骨)
- 前回まで動いているもの: Part 1-3 の打ち手(naive → hybrid+filter → rerank+citations)。ただし「よくなった」はすべて代表クエリの眺め。
- まだ壊れているもの: 客観評価が無い。だから 英語 reranker のような『改善のフリをした悪化』が潜んでいても気づけない。
- 今回直す failure mode: 「良くなった気がする」を数値化し、自分の改善を疑う装置(golden set + RAGAs)を作る。
- 今回は直さないもの: online 運用(PII / drift / cost / rollback)→ Part 5。
- 今回の合格条件: 30 件 golden で Part 間 delta が読める / negative query で「判断できません」が出る / regression を検出できる / 自分の案件の受入 gate を書ける。
この連載で一番伝えたいのは、実は 「RAG は作るより測る方が難しい」 ということです。Part 1-3 はどれも「良くなった気がする」打ち手でした。それが本物だったかは、ここでしか分かりません。だから Part 4 が背骨です。
最初に正直なことを書きます。RAGAs のスコアは LLM-as-judge で算出されるため、judge LLM の偏りや幻覚がスコアに直接乗ります1。本記事は「数字を絶対視する」のではなく、同じ judge / 同じ golden set で Part 1-3 を相対比較する 立場で書きます。そして本 Part には、シリーズ全体で最も大事な瞬間が含まれます — 測定が、eyeball では見抜けなかった失敗を炙り出す 瞬間です。
なぜ「評価」が連載のクライマックスなのか
Part 1 末尾で「測定は Part 4 で扱う」と約束しました。回収する理由は単純で、ここまでの 3 つの打ち手は trap rank / top-5 純度 / citation のような 個別の観測値 で語ってきたからです。
| Part | 主観評価で言えること | 客観評価で言える条件 |
|---|---|---|
| 1 (naive) | 動く / 失敗パターンが見える | 失敗を 数値で再現 できるか |
| 2 (hybrid+filter) | 旧版が落ちた / 純度が上がった | recall 以外の指標で 回帰がないか |
| 3 (rerank + citations) | trap が下がった / 引用が安定した | 本当に aggregate で改善しているか |
特に Part 3 の「trap が下がった」は要注意です。後で見るように、単一クエリの eyeball では「大勝利」に見えた reranker が、30 件の aggregate ではむしろ品質を下げていた — という逆転が、まさにこの Part で起きます。
評価視点の地図 — retrieval / generation / end-to-end
RAG の評価は 3 つの独立した層 に分かれます2。同じスコアシートでも「どの層を測っているか」を混同すると改善方向を誤ります。
| 層 | 入力 | 出力 | 主な指標 |
|---|---|---|---|
| Retrieval | query | retrieved chunks | Recall@k / MRR / Context Precision / Context Recall |
| Generation | query + retrieved chunks | answer | BLEU / ROUGE / Faithfulness / Answer Relevance |
| End-to-end | query | answer (+ citations) | Human eval / RAGAs 4 指標の和 |
Part 1-3 で見てきた trap rank や top-5 の眺めは Retrieval 層の断片 です。Generation 層に持ち込むと「retrieve できたが LLM が使わなかった」「使ったが間違って要約した」が新しい failure mode として出てきます3。RAGAs はこの 3 層のうち Retrieval 層と Generation 層をまとめて測る ことで、層を跨いだ回帰を捉えます2。
Golden set 30 件で十分の現実
「評価には 1000 件必要では」という直感は 間違い です。実務的なガイドラインは以下のような感覚です4:
| Golden set サイズ | 用途 | 信頼度 |
|---|---|---|
| 〜20 件 | 開発初期の sanity check | ✗ スコアが run-to-run で大きく揺れる |
| 30〜50 件 | 改善の方向性 (delta) を見る | △ 5pp 以上の差は信頼できる |
| 50〜100 件 | プロダクション regression test | ◯ 標準 |
| 200〜500 件 | 合成データ込みの広いカバレッジ | ◎ CI 専用 |
本シリーズは 30 件 self-curated から始めます。理由は 3 つで、手で全件レビューできる規模であること、5pp 以上の delta が run 間ノイズより大きいこと、1 件 5 分として 2-3 時間で作れることです。「質を最優先」 にしてください。100 件の雑な golden より、30 件の正確な golden の方が改善判断の役に立ちます。
30 件の構成 — 何を意図的に入れるか
companion repo の corpus/v2/golden_set.jsonl は以下の意図で 30 件を組み立てます:
- Happy (15 件): 対応する doc が corpus 内に明確に存在し、retrieve も generation も成立する想定
- Sad (10 件): 答えが出にくい難ケース。複数 doc に部分的に答えが散る ambiguous、または corpus に答えがない negative (例: 「Project Lumen 今期リリース計画は?」← 顧客 NDA で非公開設定)。
「資料からは判断できません」を返すのが正解 - Edge (5 件): filler 文書が genuine になる端 (例: 「お菓子コーナーの支払い方法は?」) や、表層 trap が刺さるクエリ
Sad の negative を意図的に混ぜることで、「とりあえず何か返す」モード に堕ちていないかを Faithfulness が炙り出します。Part 1-2 で仕込んだ trap (ボードゲーム同好会の post-mortem 構造、LT 大会の評価基準、物流ロールバック) は、この edge/sad で評価対象になります。
golden レコードの実物 — この形で自分の案件用に書く
「golden set を作る」が止まる原因の大半は、レコードの粒度が分からないことです。golden_set.jsonl の実レコードを 3 類型ぶん抜粋します。自分の案件では query / reference / expected_doc_ids を差し替えるだけで、同じ評価コードに流せます。
{"id": "happy-01", "type": "happy", "query": "リモートワーク手当はいくら?", "reference": "月 5 営業日以上の在宅勤務で月額 10,000 円。2025 年 4 月に 5,000 円から増額。", "expected_doc_ids": ["nagisa-remote-work"], "notes": "制度系の代表クエリ。retrieve も generation も成立する想定"}
{"id": "neg-01", "type": "negative", "query": "Project Lumen の今期リリース計画は?", "reference": "資料からは判断できません", "expected_doc_ids": [], "notes": "NDA で corpus 非収載。何かを答えたら fail"}
{"id": "edge-01", "type": "edge", "query": "ロールバックの手順を教えて", "reference": "Mirage は blue-green の切り戻しで対応する (mirage-architecture-v3)。物流のパレット戻しではない", "expected_doc_ids": ["mirage-architecture-v3"], "notes": "表層一致 trap (lumen-rollback-pallet) を踏まないかを見る"}reference は「模範解答の文章」ではなく 採点者が照合できる事実の列挙 で書きます。長い美文にすると、judge が文体の一致を採点し始めて指標が濁ります。notes には「このレコードで何を検出したいか」を 1 行残します — 半年後の自分が、落ちたレコードを見て意図を思い出せるように。
golden set を 2〜3 時間で作る手順
30 件は、まとまった半日ではなく 1 回の作業セッションで作り切れます。実際にやる場合の時間割はこうなります。
- 45 分 — 実ユーザの質問源 (問い合わせログ、Slack の質問チャンネル、FAQ への検索ワード) から候補を 40 件集める。無ければ各部署の同僚に「この bot に何を訊きたいか」を 3 件ずつ出してもらう
- 30 分 — 重複を畳んで 30 件に絞り、happy 15 / sad 10 / edge 5 に割り付ける。negative が 3 件未満なら意図的に作る
- 60 分 — 各クエリに reference と expected_doc_ids を書く。reference が書けないクエリは corpus 側の欠落 なので、削除せず corpus inventory (Part 1) に「文書が無い」として記録する
- 30 分 — 別の人に 5 件 spot review してもらう。「この reference は本当に正か」の他者チェックが、self-curated golden の最大の弱点を補う
3 の「reference が書けない」が実は最大の収穫です。RAG をいくら改善しても、corpus に答えが無い質問には答えられません。golden set 作りは、corpus の穴を見つける作業でもあります。
RAGAs 4 指標 — 何を測り、何を測らないか
RAGAs5 は LLM-as-judge ベースの評価ライブラリです。本記事では 4 つの中核指標を扱います。
Faithfulness — claim と context の整合性
Faithfulness は「生成 answer 内の claim が retrieved context で裏付けられる割合」です6。judge LLM は answer を「事実 claim」に分解し、各 claim について context 内から evidence を探し、見つかれば 1、見つからなければ 0 を付けます。Part 3 で Citations API を導入したことが直接効くのは ここ です。
Answer Relevance — query と answer の対応
Answer Relevance は「answer が query の問いに答えているか」を測ります7。judge LLM が answer から「逆問い」を N 件生成し、元 query とのコサイン類似度の平均を取ります。「query と全く関係ない正論」を返すと低スコアになります。
Context Precision — retrieved の中で本当に有用な割合
Context Precision は retrieved chunks のうち、reference を導くのに 実際に役立つ chunk の比率 を順位重み付きで測ります8。順位重みがついているので 「上位に relevant を集める」 ことを評価します。Part 3 の cross-encoder rerank で top-3 に relevant を集中 させたことが、この指標を直接押し上げます。
Context Recall — reference の claim を context がカバーしているか
Context Recall は reference answer 内の claim のうち、retrieved context が裏付けられる割合です9。「retrieved chunks に答えがそもそも含まれていない」状態をここで検出します。Part 2 の hybrid 検索が top-5 の純度を上げたことは Context Recall を押し上げる方向の打ち手です。
4 指標の相関と直交
4 指標は独立ではありません。特に 「Faithfulness ↑ + Answer Relevance ↓」(context にあることは正しいが聞かれた問いに答えてない) の組み合わせは、Faithfulness だけ追いかける危険性 を示します。4 指標を必ず併記 してください。後で見る実測でも、まさに Answer Relevance だけが他と逆の動きをします。
RAGAs を Part 1-3 に当てる (Ollama judge)
実装は companion repo の examples/evaluate.py にまとまっています。RAGAs 0.4.x の collections API を、judge も embedding も Ollama に向けて使います10。
from openai import AsyncOpenAIfrom ragas.llms import llm_factoryfrom ragas.metrics.collections import ( Faithfulness, AnswerRelevancy, ContextPrecision, ContextRecall,)
# Ollama の OpenAI 互換エンドポイントに向けるclient = AsyncOpenAI(base_url="http://localhost:11434/v1", api_key="ollama")llm = llm_factory("qwen3:8b", client=client, temperature=0)実装でハマった 2 つの罠 (Qwen3 を judge にする時)
ローカルの thinking 系モデルを RAGAs の judge にすると、素朴には動きません。2 つ実機で踏みました:
- reasoning leak: Qwen3 は既定で思考を
reasoningフィールドに吐き、contentが空のまま max_tokens に到達 → instructor が JSON を parse できず retry 枯渇で落ちます。Ollama の OpenAI 互換経路では/no_thinkもchat_template_kwargsも効かず、reasoning_effort: "none"だけが思考を抑止 しました (実測で確認)。 - 反復 degeneration: それでも稀に
"当社の当社の当社の…"の無限反復に陥り token を食い潰します。frequency_penalty=0.3で抑止し、加えて 1 指標が落ちても run 全体を止めない per-metric ガードを入れました。
「ローカル LLM を評価器にする」は、API を叩くより一段地味な落とし穴があります。これも 0 円再現の代償の一部です。
gen も judge も qwen3:8b — self-preference は避けられない
v1 の本記事は generation=Claude / judge=gpt-4o-mini と 別ベンダ にして self-preference バイアスを回避していました。けれど 16 GB Mac の 0 円経路では、generator も judge も同じ qwen3:8b を共用します。judge は自分が書きそうな answer を高く評価する傾向11があるので、絶対値は構造的に高めに出ます (この後 Faithfulness が naive でも 0.97 になるのはこのため)。
これは「バグ」ではなく このシリーズの再現条件そのもの です。だからこそ繰り返します — 絶対値を信じず、同じ judge で測った Part 間の delta を読みます。self-preference を読者が自分の Mac で観測できる、とも言えます。
30 件回した結果 — 測定が逆転を炙り出す
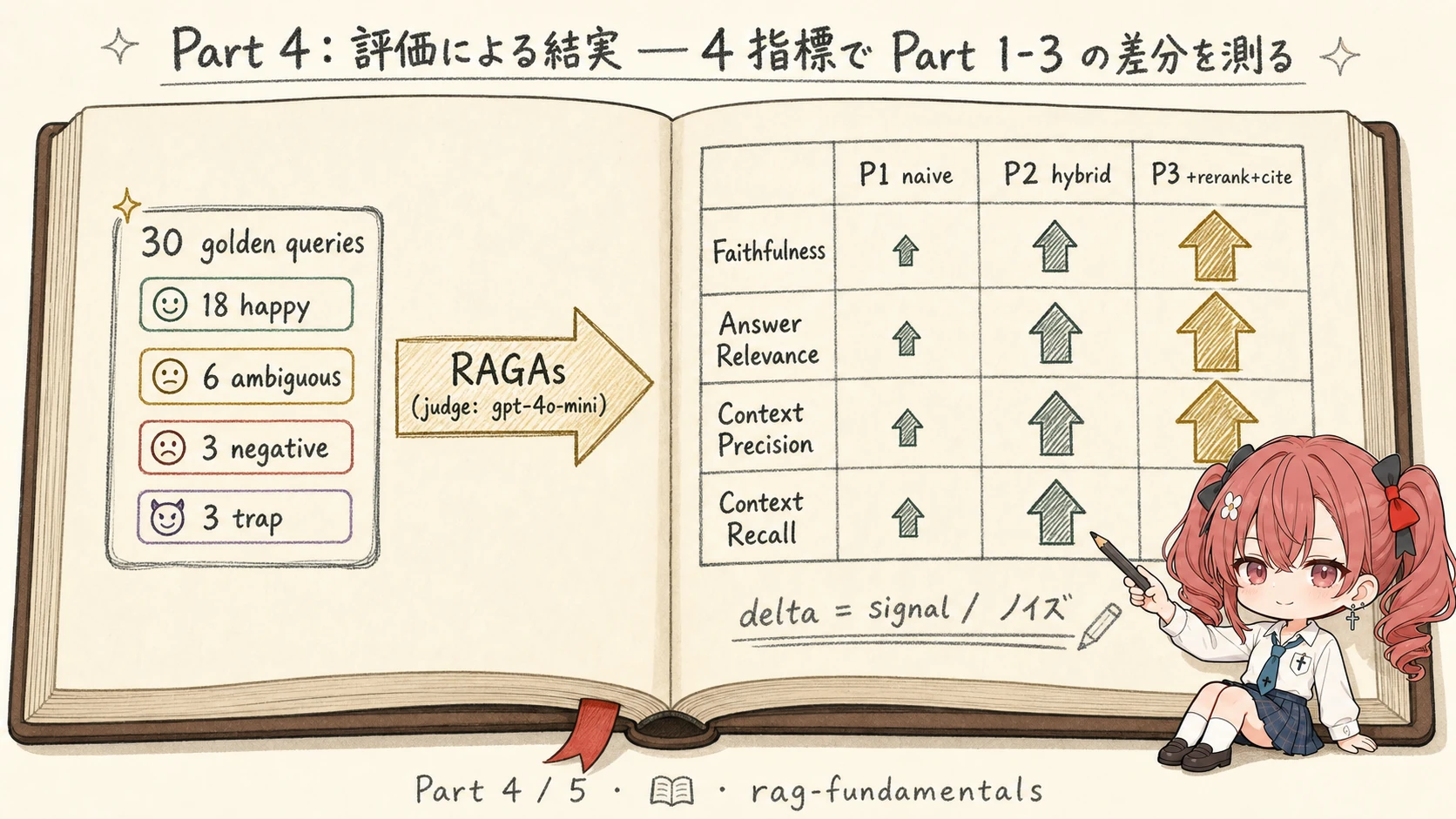
30 件を回した実測値です。judge = qwen3:8b × 1 seed の単一 run であり、絶対値ではなく Part 間の delta を信号として読んでください。
Part 1-3 を 30 件 golden set × RAGAs 4 指標で評価
judge: qwen3:8b (Ollama), 30 件 self-curated golden set (happy 15 / sad 10 / edge 5), 1 seed。gen も judge も qwen3:8b なので絶対値は self-preference で高めに出る — delta を信号として読む
| Pipeline | Faithfulness | Answer Relevance | Context Precision | Context Recall |
|---|---|---|---|---|
| P1: naive (Part 1) | 0.968 | 0.533 | 0.761 | 0.817 |
| P2: hybrid+filter (Part 2) | 0.986 | 0.528 | 0.836 | 0.867 |
| P3: + rerank + Citations (Part 3) | 0.990 | 0.512 | 0.906 | 0.850 |
読み取れること:
- Context Precision が 0.76 → 0.84 → 0.91 と単調上昇: rerank の本領。top-3 に relevant を集中させた効果が aggregate で +14.5pp として確認できます。本シリーズで最も綺麗に効いた指標
- Faithfulness が 0.97 → 0.99: 既に高いが単調上昇。Citations の grounding が claim-evidence 紐付けを微改善 (絶対値が高いのは self-preference)
- Context Recall は P2 が最良 (0.87)、P3 で微減 (0.85): top-3 まで絞った副作用。許容範囲だが、k=3 がトレードオフを生むことが数値で見える
- Answer Relevance だけ横ばい〜微減 (0.53 → 0.53 → 0.51): 唯一改善しない指標。answer は全 pipeline で同じ「chunk 連結」スタブなので、retrieval 品質が上がっても answer の言い回しは変わらず、ここは判定ノイズ範囲。4 指標を併記しないと「全部良くなった」と誤読する 好例
測定が捕まえた失敗 — 英語 reranker の罠
ここが本 Part のクライマックスです。Part 3 で触れた通り、最初は reranker に 英語の ms-marco-MiniLM-L-6-v2 を使っていました。単一クエリ (コードレビュー) の eyeball では、trap を rank 2 → 9 まで突き落とし、大勝利に見えました。
ところが同じ 30 件を ms-marco で測ると:
| Pipeline (reranker) | Context Precision | Context Recall |
|---|---|---|
| P2: hybrid+filter | 0.836 | 0.867 |
| P3: ms-marco (英語) | 0.597 | 0.656 |
| P3: bge-m3 (多言語) | 0.906 | 0.850 |
英語 reranker は、日本語の chunk をほぼランダムに並べ替えて関連 chunk を取りこぼし、P3 を P2 より大幅に悪化 させていました (CR 0.87 → 0.66)。単一クエリの eyeball test では絶対に気づけなかった回帰です。これに気づけたのは 30 件を測ったから で、多言語 bge-m3 に切り替えて初めて P3 が P2 を上回りました (上表)。
これが「評価」が連載のクライマックスである理由 です。retrieval を真面目にし、引用を付け、reranker を足し — どれも「良くなった気がする」打ち手でした。けれど 測って初めて、その 1 つが実は品質を下げていた ことが分かります。offline 評価は、自分の改善を疑うための装置です。
P3 の Faithfulness 0.99 を「絶対的に良い」とは読めません。Stanford 2025 の legal RAG 研究では purpose-built システムでも 17-34% の hallucinate が報告されています12。self-preference で高く出た 0.99 を真に受けず、delta と相対順位 で読むのが正しい姿勢です。
LLM-as-judge の良いところと悪いところ
RAGAs のスコアは LLM-as-judge です。注意点を整理します。
- 同型バイアス (self-preference): gen=judge=qwen3:8b の本構成では構造的に乗ります11。絶対値を内部比較にしか使えません。別ベンダ judge (gpt-4o-mini 等) を使えば緩和できますが、それは 0 円経路を捨てることを意味します
- 位置バイアス: 複数 answer を比較する時は順序 swap して平均13。本記事は指標単独 scoring なので影響小
- Verbosity / Style bias: 長い・整然とした answer を高評価しがち14。answer 長を pipeline 間で揃える (本記事は同じスタブ)
- Cost / Latency: 30 件 × 4 指標 × 3 pipeline = 360 judgement / run。Ollama qwen3:8b で Apple Silicon 1 時間強。CI 毎 PR は非現実的で、nightly cron + 主要 PR 手動 trigger が現実解
で、何点なら本番に出していいのか — 受入 gate を設計する
ここまでで読者が一番訊きたいのは 「で、結局何点なら本番に出していいの?」 だと思います。正直に言うと、絶対値で gate を引くのは危険 です。self-preference や seed で絶対値は動くからです(だから 0.99 を真に受けてはいけない、と繰り返しました)。
だから本番投入の判断は、絶対スコアではなく gate(合格条件) で設計します。以下はナギサ案件向けの例で、自分の案件の数字に置き換えて使う 成果物です。
本番投入 gate の例(自分の案件向けに書き換える)
最低条件(1 つでも欠けたら出さない)
- negative query で「資料からは判断できません」が 90% 以上 出る
- archived / draft chunk が top-k に混入しない
- PII redaction の unit test が通る
- golden set で 前回比 -5pp 以上の regression が無い(delta ベース)
推奨条件(出せるが、できれば満たす)
- Context Precision が baseline 比 +10pp 以上
- Context Recall が baseline 比 -3pp 以内(rerank の副作用を許容範囲に)
- human spot check 20 件で 重大誤答 0 件
- rollback 手順が 15 分以内 に実行できる(Part 5)
ポイントは delta(前回比)と human spot check を主役にする こと。LLM-as-judge の絶対値は補助線にすぎません。この gate を一度書いておけば、以降の変更は「gate を通るか」で機械的に判断でき、記事が「読むもの」から「案件で使うもの」に変わります。
評価レポートの記入テンプレート
gate と並ぶもう 1 つの成果物が、変更のたびに残す評価レポートです。長い文書は続かないので、PR の description にそのまま貼れる分量に畳みます。
# RAG 評価レポート {YYYY-MM-DD}- 変更点 (1 行): {例: reranker を ms-marco から bge-reranker-v2-m3 に変更}- golden set: v{N} ({30} 件 / happy {15} / sad {10} / edge {5})- judge: {qwen3:8b (gen と同型、self-preference あり)} / seed: {single run}
| pipeline | Faithfulness | Answer Rel. | Ctx Precision | Ctx Recall || -------- | ------------ | ----------- | ------------- | ---------- || 変更前 | | | | || 変更後 | | | | || delta | | | | |
- 受入 gate 判定: 最低条件 {4}/{4} pass / 推奨条件 {N}/{4} pass- negative の挙動: {「判断できません」が 10/10 件で出た}- 落ちたレコードと所感: {id と 1 行ずつ}- golden set への追加候補: {今回の失敗から}「落ちたレコードと所感」を空欄のまま提出しない、が運用の肝です。aggregate の数字だけ見て個別レコードを読まないと、英語 reranker の罠のような「平均は上がったが特定類型が全滅」を見逃します。
Offline → Online への橋渡し
Part 4 で組んだ「30 件 × 4 指標」は offline batch 評価 です。本番では別の現実があります。
| 観点 | Offline (Part 4) | Online (Part 5) |
|---|---|---|
| データソース | 自前 golden set 30 件 | 実ユーザ query (PII 含む) |
| 評価頻度 | nightly + 主要 PR | 全 query (sampling 可) |
| 評価主体 | LLM-as-judge + 人手 spot check | user feedback + LLM-as-judge |
| 反映先 | golden の合格基準 | dashboard / alert / rollback |
| ハマりどころ | judge bias / reranker の言語適合 | logging の PII / drift / cost |
Offline が「変更前後で回帰がないか」を見るのに対し、Online は「現実が想定通り動いているか」を見ます。本 Part で英語 reranker の回帰を捕まえたように、両方が揃って初めて RAG は production-ready です。
Part 5 では online 側で必須になる Logging の設計と PII redaction、embedding drift 検出、古い文書の freshness 退役 (Part 2 の宿題)、コスト構造、インシデント対応とロールバック を扱います。本 Part の 4 指標 dashboard が、Part 5 で online metrics に 接続 されます。
この Part で手元に残る成果物
ここが連載で最も重要な成果物です。読み終えた翌日に書けるべきは、まさにこの 3 つ。
- golden set(30 件): happy / sad(negative 含む)/ edge を混ぜた、自分の corpus 向けの正解集合
- RAGAs 評価レポート: 自分の pipeline 変更を 4 指標 × Part 間 delta で並べた表(絶対値ではなく delta を読む)
- 本番受入 gate: 上の「最低条件 / 推奨条件」を自分の案件の数字で書いたチェックリスト
次の Part に進む条件
- 自分の golden set で、ある変更が 改善か悪化かを delta で判定 できた
- negative query で「判断できません」が返ることを確認した
- 受入 gate を 自分の言葉で 1 枚 にした(Part 5 の運用 checklist と接続する)
シリーズ全体: 使える RAG の作り方 — 測って・直して・運用する
次回 Part 5 (完結): 「本番運用 — Logging Safety / Drift / Cost / Rollback」
参考文献
Footnotes
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena — Zheng et al., NeurIPS 2023。LLM-as-judge の偏り (position / verbosity / self-preference) を初期に定量化した基礎論文 ↩
Ragas: Automated Evaluation of Retrieval Augmented Generation — Es et al., EACL 2024。retrieval / generation / E2E の 3 層分離評価モデル ↩ ↩2
Evaluation of RAG Metrics for Question Answering in the Telecom Domain — 2024。retrieve と generation で failure mode が分かれる実証 ↩
RAG Evaluation: Metrics, Frameworks & Testing (2026) — 30-100 件の golden が「十分」のラインに落ち着く実務観 ↩
Ragas - Supercharge Your LLM Application Evaluations — 公式 docs。0.4 で collections API に移行 ↩
Faithfulness - Ragas — claim 分解 → context 内 evidence 検証の二段アルゴリズム ↩
Response Relevancy - Ragas — 逆問い生成 + embedding cosine の二段 ↩
Context Precision - Ragas — Precision@K の順位重み付き平均 ↩
Context Recall - Ragas — reference claim 単位の retrieved 裏付け率 ↩
ragas · PyPI — 0.4.x 系の API リファレンス ↩
Self-Preference Bias in LLM-as-a-Judge — 2024。generator と judge が同モデルの場合 self-preference が観測される定量研究 ↩ ↩2
Hallucination-Free? Assessing the Reliability of Leading AI Legal Research Tools — Stanford 2025。purpose-built RAG でも 17-34% hallucinate ↩
Large Language Models are not Fair Evaluators — Wang et al., 2023。位置バイアス (順序効果) を実証 ↩
Length Bias in LLM-as-a-Judge Evaluations — verbosity bias の定量化と緩和策 ↩