
素朴な RAG の限界 — 100 行で動くけど「使える」とは言えない理由
2026-05-24 改訂: 本シリーズは API キー無しの完全ローカル環境 (Ollama + Qwen3) で再現できる 構成に作り直しました。本文の検索スコア・回答例は、すべて
qwen3-embedding:0.6b+qwen3:8bで 実測した値 です。題材は架空企業「ナギサ・パートナーズ」の社内 wiki に統一し、companion repo の corpus も差し替えています。ollama pullだけで手元で同じ数字を再現できます。なお速度の目安として、Part 1-3・5 の 単発クエリは数秒 で返りますが、Part 4 の一括評価 (RAGAs 30 件 × 3 パイプライン) は Apple Silicon で 1 時間強 かかります (Part 4 で代表 10 件の短縮経路も案内します)。「無料 (0 円)」と「高速」は別物で、ローカル LLM では一括バッチが律速になります。
「ChatGPT に社内ドキュメントを参照させたい」「自社の FAQ から正確に答えてほしい」。RAG (Retrieval-Augmented Generation) はこの種の要望にもっともよく当てはまる手法 で、検索すれば「RAG 入門」記事は無数に出てきます1。けれど、ほとんどは「動くサンプル」で止まり、本番投入したらすぐに「あれ、これは使えないぞ」と気付くことになります。
この記事では、まず 100 行強の Python で素朴な RAG を組み立てます。ローカルの Ollama に載せた埋め込みモデルと LLM の組み合わせで、corpus 読み込みから生成まで本当に短く書けます。その上で、動いて見える その実装が なぜ本番では使えないか を、実際に流して観察します。読み終わったとき、シリーズの残り 4 部 (Retrieval / Generation / Evaluation / Operations) で何を解決したいかが、読者自身の言葉で言えるようになる、というのが Part 1 の目標です。
はじめての方へ: embedding / retrieval / reranker といった用語にまだ不安があれば、先に RAG を作る前に読む地図 で「どの用語がどの工程で効くか」を掴んでから戻ると、この先がぐっと読みやすくなります。
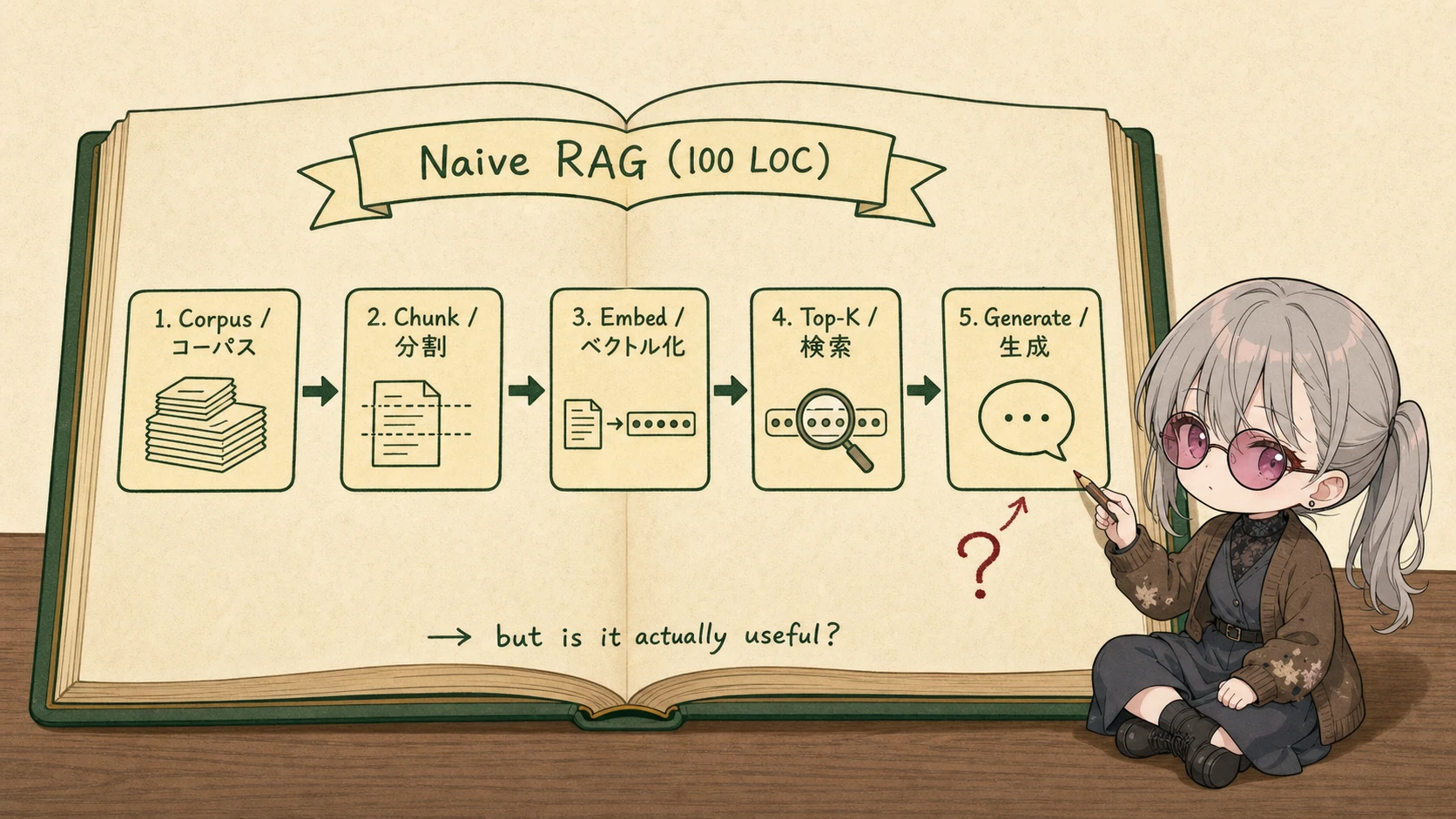
現在地 — フェーズ 0「PoC を組んで失敗を観察する」
- 前回まで: なし(出発点)。地図記事で用語と最終成果物の全体像は受け取った状態。
- まだ壊れているもの: 何も。まだ 1 行も書いていない。
- 今回直す failure mode: 何も直さない。素朴 RAG を組み、「動く」と「使える」の谷を 自分の目で観察 するのが今回の仕事。
- 今回は直さないもの: retrieval(Part 2)/ generation(Part 3)/ 評価(Part 4)/ 運用(Part 5)のすべて。
- 今回の合格条件: 4 クエリ中 3 つで trap を再現でき、top-k の中身を自分の言葉で説明できること。
RAG の定義と解く課題
RAG とは何で、何ではないか
RAG は 検索 (retrieval) を組み合わせて、生成 (generation) を補強する 手法群の総称です。Lewis et al. の論文 (2020)1 で QA タスク向けに導入され、現代では「LLM が訓練時には知らなかった外部知識を、推論時に context として差し込む」という汎用パターンの総称として使われます。
「LLM がそのまま答えても良いタスク (要約・翻訳・自由作文)」は RAG ではありません。RAG は 答えのために事実が必要で、その事実が学習データに含まれていない (または古い) タスクに使います。
実装パターンには Naive / Advanced / Modular という分類があり2、本シリーズの Part 1 は最も素朴な Naive RAG を扱います。後続の Part で改善要素を 1 つずつ載せていく形です。
いつ RAG を使うべきか
- 社内 wiki / 製品 FAQ / 技術文書のような 更新頻度が高く、ドメイン特異な知識 を扱う用途
- 「答えの根拠を提示できる」ことが要求されるアシスタント (法務 / 医療 / 経理など)
- LLM の知識更新を fine-tuning で行うには 更新頻度が早すぎる、または学習データが足りない ケース
いつ使うべきでないか
- 創造的タスク (小説・コピーライティング)。事実より文体の方が大切で、retrieval が邪魔をする
- 軽量モデルで十分な分類タスク。RAG の overhead を払う意味がない
- リアルタイム性が極端に要求される (1 秒以内の応答) 用途。embedding + retrieval + LLM 呼び出しは合計で数百 ms 〜 数秒かかる
判断軸は「変更頻度 と 正確性要求 をかけ算したときに、fine-tuning より RAG の方が割に合うか」です。社内 wiki なら毎週変わるので RAG、ブランドガイドラインなら年単位なので fine-tuning でも良い、というように。
100 行最短実装
ここから手を動かします。完成形は 100 行強の Python で、構成は以下のとおりです。
[corpus 読み込み] ↓[固定長 chunk 分割] ↓[qwen3-embedding:0.6b でベクトル化 (Ollama)] ↓[クエリも同じ embedding で表現 → cosine top-K] ↓[qwen3:8b に context として注入 → 生成 (Ollama)]セットアップ
Python は 3.11 以上、パッケージマネージャは uv を使います。LLM と埋め込みは Ollama でローカルに動かす のが本シリーズの既定経路です。
# モデルを取得 (合計 ~6 GB、16 GB Mac 想定)ollama pull qwen3:8bollama pull qwen3-embedding:0.6b
# サンプルリポジトリを clonegit clone https://github.com/zawazawa5809/rag-fundamentals-companion.gitcd rag-fundamentals-companiongit checkout part-01
# 依存導入uv sync --frozen
# Ollama 経路を既定にするcp .env.example .envecho "RAG_PROVIDER=ollama" >> .envAPI キーすら用意したくない場合は --mock を付けます。挙動の流れは確認できますが、本物の cosine 類似度の振る舞いは見られません。OpenAI / Anthropic の API 経路でも全く同じインターフェースで動きます (RAG_PROVIDER=anthropic_openai、詳細は companion repo の README)。
corpus と chunking
corpus は架空の中堅 SIer「ナギサ・パートナーズ株式会社」(社員約 600 名、横浜みなとみらい本社 + 大阪関西支店、受託開発 7 割 + 自社 SaaS「Mirage」3 割) の社内 wiki 風 Markdown を 15 件用意しました (corpus/v2/ 配下、全文 CC0 1.0)。意図的に「実在する社内 wiki あるある」を仕込んであります。
- そのまま正解になる文書 (5 件): リモートワーク制度 / 経費精算 / 障害対応フロー / 社内ヘルプデスク FAQ / 自社プロダクト Mirage の現行アーキ (v3.2)
- 語が一致するが意味は別物の trap (3 件): ランニング部の練習「計画」/ 顧客満足度 (CSAT) 調査の「顧客」/ 物流倉庫の「ロールバック」(誤出荷品のパレット戻し作業)
- 構造・テンプレが似ているだけの trap (3 件): ボードゲーム同好会の月例「post-mortem」/ 社内 LT 大会の「評価基準」/ オフィス入退館の物理「セキュリティ」
- 古い版が archive されず残っている trap (2 件): 経費精算の 2023 旧版 / Mirage アーキ v2 (2023 公開、現行は v3.2)
- どのクエリにも当たらない雑文書 (2 件): お菓子コーナー運用 / 新人 onboarding チェックリスト
「同じ製品の設計書が v2 と v3 で並んでいて、どれが正かわからない」「物流の『ロールバック』と IT の『ロールバック』が同じ言葉で書かれている」「同好会の振り返りが障害対応の post-mortem と全く同じテンプレで書かれている」 — これは 多くの企業の社内 wiki にある現実そのまま で、本シリーズで取り組む課題の本丸です。
CHUNK_SIZE = 600CHUNK_OVERLAP = 100
def chunk(docs): """Fixed-size sliding window. Returns [(chunk_id, text), ...].""" out = [] step = CHUNK_SIZE - CHUNK_OVERLAP for doc_id, body in docs: n = max(len(body) - CHUNK_OVERLAP, 1) for i, start in enumerate(range(0, n, step)): piece = body[start : start + CHUNK_SIZE] if piece.strip(): out.append((f"{doc_id}#{i:02d}", piece)) return out固定 600 字 / overlap 100 字 という値は LangChain や LlamaIndex のデフォルト周辺の典型値です34。意図的に意味境界 (文末・段落・H2) を尊重していません。これは Part 2 で recursive / semantic chunking との差を作る伏線です。この素朴な分割で 15 docs が 47 chunk になります。
埋め込み
埋め込みは Ollama 経由の qwen3-embedding:0.6b を使います。qwen3-embedding ファミリは MTEB 多言語リーダーボードで上位 (8B 版が 2025 年 6 月時点で 1 位)5 で、その最軽量 0.6B 版は 16 GB Mac でも軽く動きます (47 chunk の埋め込みは数秒)。日本語の社内文書でも十分な検索品質が出ます。埋め込みは軽い一方、生成・評価に使う 8B の LLM がローカルでは律速になる点は後で効いてきます。
class _OllamaEmbed: def __init__(self, model="qwen3-embedding:0.6b"): from ollama import Client self._model = model self._client = Client()
def embed(self, texts): res = self._client.embed(model=self._model, input=texts) return [list(v) for v in res.embeddings]corpus 側のベクトルは offline で一度だけ計算し、クエリ側はリクエストごとに計算します。本格運用なら vector DB を挟みますが、Part 1 はメモリ上の numpy 配列で十分です。OpenAI text-embedding-3-small などに差し替えても同じ embed(texts) インターフェースで動きます。
Retrieval (cosine top-k)
def cosine_topk(query_vec, doc_vecs, k): q = np.array(query_vec, dtype=np.float32) M = np.array(doc_vecs, dtype=np.float32) sims = M @ q / (np.linalg.norm(M, axis=1) * np.linalg.norm(q) + 1e-9) idx = np.argsort(-sims)[:k] return [(int(i), float(sims[i])) for i in idx]M @ q で全 chunk と一発で内積を取り、/ (||M|| * ||q||) で正規化して cosine 類似度を得る、numpy 一行勝負です。corpus が数万件を超える前は素朴な行列演算で十分速いです。+ 1e-9 はゼロ除算回避。
生成 (Qwen3)
def build_prompt(query, retrieved): ctx = "\n\n".join(f"### {cid}\n{txt}" for cid, txt, _ in retrieved) return ( "<context>\n" f"{ctx}\n" "</context>\n\n" f"<question>{query}</question>\n\n" "上の context のみを根拠に、3-4 文で答えてください。" )XML タグでセクションを区切るのは多くの LLM で有効な指針で6、ここでも <context> と <question> で構造化しています。生成自体は Ollama の chat() を 1 回呼ぶだけ (qwen3:8b)。Claude を使う場合は client.messages.create(...) に差し替えるだけです。
完成形のフルコード (約 105 行) は companion repo の examples/naive_rag.py で見られます。
動かして眺める
ここからが本題です。1 つの素直なクエリと、3 つの「困る」クエリを流して挙動を観察します。
注: 以下の transcript は
RAG_PROVIDER=ollamaで実際に流した結果です。検索スコア (cosine) は決定的で安定 していますが、qwen3:8bの生成文言は run ごとに揺らぐので、自分で再現する場合は wording が異なる可能性があります。uv run python -m examples.naive_rag --query "..."で確かめてみてください。
§3.1 素直なクエリ: 「リモートワーク手当はいくら?」
まずは制度ものから。社内 bot として最も多い類型の質問です。
uv run python -m examples.naive_rag --query "リモートワーク手当はいくら?"[corpus] 15 docs, 47 chunks[retrieve] top-k: 0.5202 nagisa-remote-work#00 0.4043 nagisa-remote-work#01 0.3840 nagisa-onboarding-checklist#02
[answer]リモートワーク手当は、月に5営業日以上在宅勤務した場合、月額10,000円が支給されます。この金額は、2024年度までの5,000円から2025年4月に増額されたものです。支給対象月は出勤記録(kintone)で自動判定され、在宅勤務日数が5日未満の月は対象外です。観察ポイント: 「リモートワーク」「手当」というクエリ語彙が nagisa-remote-work.md と一致し、top-1・top-2 をその文書が占めます。回答は金額・改訂・判定条件まで正確です。これが「動く RAG の最良ケース」、すなわち クエリ語彙と文書語彙が一致した社内 FAQ の挙動です。社内 bot で多くの質問はこのパターンで答えられます。
なお top-1 の cosine が 0.52 と、ベクトル検索のイメージより低めに見えるかもしれません。これは qwen3-embedding が日本語短文クエリと長文 chunk の間で出す典型値で、絶対値の高さより「正解 chunk が他を引き離して 1 位か」が本質 です。この後の trap では、この「引き離し」が崩れます。
§3.2 古い設計書が先頭に来る: 「Mirage 現行アーキテクチャの認証経路は?」
ここから雲行きが怪しくなります。同じ製品の設計書が v2 と v3 で並んでいる corpus に対して、エンジニアが普通に訊きそうな質問を投げます。
uv run python -m examples.naive_rag --query "Mirage 現行アーキテクチャの認証経路は?"[corpus] 15 docs, 47 chunks[retrieve] top-k: 0.6515 mirage-architecture-v2-archive#00 0.5998 mirage-architecture-v3#00 0.5770 mirage-architecture-v3#04
[answer]Mirage 現行アーキテクチャ(v3)の認証経路は、Keycloak(OIDC provider)を採用しています。v2 の BASIC 認証 + JWT から置換され、OIDC サービスとして統合されています。認証フローは Keycloak が担い、トークンの発行・検証が行われます。観察ポイント: 答え自体は正しいです (現行 v3 は Keycloak/OIDC)。しかし top-k を見てください。「現行アーキテクチャ」と訊いたのに、top-1 は mirage-architecture-v2-archive — 2023 年の旧版設計書 です。現行の mirage-architecture-v3 (0.5998) を、archive 済みの旧版 (0.6515) が押しのけて 1 位に来ています。
なぜか。旧版の冒頭には「Mirage アーキテクチャ v2 (2023 年度版・旧版)」という見出しと構成サマリが詰まっていて、「Mirage」「アーキテクチャ」「認証」というクエリ語との表層一致が現行版より濃い のです。embedding は「これは archive 済みの古い文書だ」というメタ情報を区別しません。
今回 LLM はたまたま v2/v3 の差を読み取って正しく答えました。でも、それは 運 です。素朴な RAG には「現行を旧版より優先する」仕組みが一切ありません。旧版 chunk が context の先頭を占め続ければ、いつか「Mirage の認証は BASIC + JWT です」と、2 年前に廃止された方式を自信満々に答える日が来ます。
mirage-architecture-v2-archive.mdの冒頭にはちゃんと「⚠️ Archive 注記: 現行は v3」と書いてあります。けれど、その注記が 検索された chunk に含まれていなければ生成側には存在しないも同然 です。固定長分割は注記とは無関係な場所で chunk を切るので、注記が落ちることが珍しくありません。
これは Part 2 (metadata 保持型 chunking で版・status を chunk に焼き込む) + Part 5 (freshness / status filter で archive を index から外す運用) の二段で扱います。
§3.3 語が一致するだけの trap: 「ロールバックの手順を教えて」
今度は、エンジニアが Mirage の障害対応を念頭に「ロールバック」を訊いたつもりのクエリです。
uv run python -m examples.naive_rag --query "ロールバックの手順を教えて"[corpus] 15 docs, 47 chunks[retrieve] top-k: 0.6501 mirage-architecture-v2-archive#02 0.6074 lumen-rollback-pallet#00 0.5825 lumen-rollback-pallet#01
[answer]ロールバック手順は、発生場所によって分かれます。倉庫内での発見の場合、該当パレットを退避し WMS で「ロールバック中」とステータス更新後、再検品・理由入力を行い元の棚に戻します。配送中での発覚は、配送業者に「全件戻し」を連絡し再配送を依頼、受け取ったパレットを一時ヤードに保管し、翌営業日に再検品・再格納を行います。観察ポイント: 回答が 完全に物流倉庫の話 になっています。パレット、WMS、再検品、配送業者 — IT デプロイのロールバック (mirage-architecture-v3.md の blue-green switch back) とは何の関係もありません。
corpus には lumen-rollback-pallet.md という、大手物流顧客 Project Lumen の倉庫オペレーション手順書が入っています。物流業界では「ロールバック」「巻き戻し」「戻し作業」「再格納」が 誤出荷品をパレット単位で倉庫に戻す作業 を指します。クエリに「Mirage」も「デプロイ」も付けなかったため、embedding は「ロールバック」という 語の表層一致 だけで物流文書を top-2/3 に引き上げ、LLM はそれを忠実に要約しました。
これが 表層一致トラップ です。cosine 0.60 は嘘ではありません — 「ロールバック」という語が本当に何度も出てくるのです。けれど 語が一致することと、意味が関連することは別 で、素朴な RAG はそれを区別できません。(おまけに §3.2 と同じく、ここでも archive 済み v2 が top-1 に居座っています。)
これは Part 3 (cross-encoder reranker で意味的関連性を再採点 + 引用付き生成で「どの文書由来か」を露出) で扱うパターンです。
§3.4 構造が似ているだけの trap: 「月例の振り返り会はどう進めればいい?」
最後は、運用改善の文脈で「振り返り会の進め方」を訊いた、ごく自然な質問です。
uv run python -m examples.naive_rag --query "月例の振り返り会はどう進めればいい?"[corpus] 15 docs, 47 chunks[retrieve] top-k: 0.4938 nagisa-boardgame-monthly#02 0.4886 nagisa-boardgame-monthly#04 0.4507 nagisa-boardgame-monthly#03
[answer]月例振り返り会は、blameless な姿勢で「タイムライン・直接原因・根本原因・次回アクション」を軸に進めます。社内 wiki に月次集計を投稿し、卓リーダーが初期対応を確認したインシデントを対象に議論します。今月は P1 課題として、post-mortem 型から「やったこと/学び/次やる」型のテンプレートに簡素化し、5 月幹事会で議論する必要があります。観察ポイント: top-3 をすべて nagisa-boardgame-monthly — ボードゲーム同好会の 4 月活動報告 が占めています。回答には「blameless」「タイムライン・直接原因・根本原因」「卓リーダー」「P1 課題」「初動 acknowledge」 — 障害対応 post-mortem の語彙と、同好会の「卓リーダー」がシュールに混ざっています。
なぜか。ボードゲーム同好会の月例報告は、業務の incident post-mortem テンプレを意図的に流用 して書かれているのです (「TL;DR / やったこと / 振り返り / Next Action」「acknowledge」「初動 SLA」「エスカレーション基準」)。embedding は 意味よりも文体・構造・段落リズムを強く拾う ため7、「振り返り会の進め方」というクエリに対して、本物の障害対応フロー (nagisa-incident-flow.md) ではなく、構造がそっくりな同好会の報告を「似ている」と判定しました。
これが 構造類似トラップ です。見かけ上の出力が流暢なので、読者が「卓リーダーって何?」と引っかかるまで誰も間違いに気付きません。社内ナレッジボットで最も発見が遅れる失敗です。Part 2-3 の cross-encoder reranker で部分解消するパターンです。
観察した失敗を分類する
§3 で 4 つのクエリを流しました。1 つは成功、3 つで「retrieval が間違った文書を拾う」様子を見ました。抽象化すると、素朴な RAG の弱点は 3 つのグループ に整理できます。
グループ A: retrieval が「間違った文書」を拾う
corpus に紛れた trap 文書を、本物より上位に引き上げてしまうパターン。3 類型あります。
| # | trap 類型 | §3 の実例 | なぜ起きる | 解決する Part |
|---|---|---|---|---|
| A-1 | 表層一致 (surface) | §3.3 物流ロールバック | 語が一致するだけで意味は無関係 | Part 3 (rerank + 引用) |
| A-2 | 構造類似 (semantic) | §3.4 ボドゲ post-mortem | テンプレ・文体が同じ | Part 3 (rerank) |
| A-3 | 古い記述 (stale) | §3.2 Mirage v2 archive | 旧版が現行を押しのける | Part 2 (部分) + Part 5 (filter) |
A-1 と A-2 は「距離は近いのに内容は無関係」という同じ根を持ちます。embedding は語の表層や文章構造を拾うので、「ロールバック」という単語や「post-mortem テンプレ」という骨格が一致しただけで高スコアを出します。cross-encoder reranker (Part 3) はクエリと chunk を 同時にエンコードして相互注意で関連性を再採点 するので、表層・構造の一致に引きずられにくくなります。
A-3 (古い記述) は別の根です。文書は本物 (Mirage の設計書) なのに 版が古いのです。これは「どれが現行か」という メタ情報の問題 で、retrieval スコアだけでは解けません。Part 2 で版・status を chunk に焼き込み、Part 5 で「archive を index から外す」運用に落とします。
グループ B: retrieval が「正しい文書」を取りこぼす
逆に、本物の文書が 語彙のズレ で圏外に落ちるパターンです。社内文書あるあるで「リモワ」「テレワーク」「WFH」「在宅勤務」がすべて同じ制度を指す、「障害」「インシデント」「トラブル」「P1」が併用される — のような synonym / acronym 過密ドメイン で頻発します8。
たとえば「テレワークの補助金はある?」と訊いたとき、nagisa-remote-work.md が「在宅勤務手当」と表記しているために cosine が下がり、回答に必要な doc が top-3 圏外に落ちることがあります (§3.1 では「リモートワーク手当」と語が揃っていたので拾えました)。
Part 2 で解決: BM25 (sparse) + embedding (dense) を組み合わせ、Reciprocal Rank Fusion (RRF) でスコアを合成する hybrid search にすると、acronym 一致 (BM25 が拾う) と意味類似 (embedding が拾う) を両取りできます。
グループ C: generation 側で壊れる
retrieval が正しくても、生成の段で品質が落ちるパターンが 2 つあります。
C-1 引用 (出典) が消える: build_prompt で ### mirage-architecture-v3#00 のようなラベルを context に入れても、生成では chunk ID への参照が出力に残らない ことが多いです。すると、本物の回答であっても 「どこから来た事実か」を読者が検証できません9。§3.2 で見た「現行 v3 か旧版 v2 か」を読者が見分けられないのと直結します。Part 3 で解決: [citation: doc_id] 形式の明示要求 + parser、または Anthropic の Citations API9 (doc_id + 該当箇所の charspan まで返す) を使う設計に切り替えます。
C-2 コンテキスト爆発: 「精度が悪い、もっと取れば?」と top-k を 3 → 10 → 30 に増やすと、input token が増えてコストが跳ね、long context の needle-in-a-haystack 性能はむしろ劣化し10、関連しない chunk が増えて hallucination も増えます。top-k を増やすほど答えが良くなる、わけではありません。Part 3-4 で解決: reranker で top-k=20 → top-3 に絞り、Part 4 で Context Precision / Context Recall を数値で測定 して trade-off を可視化します。
自分の corpus に持ち帰る — 失敗を「設計課題」に変える
ここまでの trap はナギサ corpus 固有に見えますが、抽象化すると どの社内 corpus にも刺さる 5 つの設計課題 になります。Part 2 以降を読む前に、この 5 問を 自分の corpus に対して 問い直してみてください。これが本連載で最初に作る成果物です。
- Document lifecycle: active / draft / archived を、検索時に区別できるか?(旧版 trap → Part 2/5)
- Lexical ambiguity: 同じ単語が別業務で使われるとき、どう分離するか?(表層一致 trap → Part 3)
- Structural similarity: テンプレが似ている文書を、どう落とすか?(構造類似 trap → Part 3)
- Evidence visibility: 回答がどの chunk に基づくかを、利用者に出せるか?(引用喪失 → Part 3)
- Evaluation: 「良くなった気がする」を、どう測るか?(→ Part 4)
この 5 問は、本連載の残り 4 部がそれぞれ 1 つずつ答えていく問いそのものです。だから Part 2 以降に 必然性 があります。
そのまま貼るテンプレート — corpus inventory と failure case list
成果物 1 と 3 は、凝ったツールより「wiki か Issue に貼れる 1 枚」が長持ちします。次の 2 つをコピペして、自分の corpus の行で埋めてください。status 列は確信が持てなくて構いません。「archived?」のような疑問符付きの行こそが、Part 2 で metadata 抽出ルールを設計するときの入力になります。
## corpus inventory (v0)| doc_id | 所管 (owner) | status 仮 | 最終更新 | 備考 (trap 候補?) || ------ | ------------ | --------- | -------- | ----------------- || expense-rules-2023 | 経理 | archived? | 2023-04 | 現行版がどれか不明 || product-arch-v2 | 開発 | archived? | 2023-09 | v3 と並存している || club-monthly-04 | 総務 | active | 2026-04 | 業務テンプレを流用した文体 |
## failure case list| # | クエリ | 期待した doc | 実際の top-3 | 分類 || - | ------ | ------------ | ------------ | ---- || 1 | ロールバックの手順は? | product-arch-v3 | logistics-rollback, ... | A-1 表層一致 || 2 | 現行アーキの認証は? | product-arch-v3 | product-arch-v2, ... | A-3 旧版 |分類列には本記事の A-1 / A-2 / A-3 / B / C-1 / C-2 をそのまま使います。この 2 枚は Part 2 の chunking policy、Part 4 の golden set の素材になるので、走り書きでも今日のうちに作っておく価値があります。
なぜ Part 2 以降が必要か
失敗 → 残り Part の対応
ここまでで見た失敗が、残りの Part にどう対応するかの全体像です。
| グループ | 失敗 | 解決する Part | 主要手段 |
|---|---|---|---|
| A-1/A-2 | 表層・構造の trap | Part 3 | cross-encoder reranker + 引用付き生成 |
| A-3 | 古い記述 trap | Part 2 (部分) + Part 5 | metadata 保持型 chunking + freshness / status filter |
| B | 同義語で取りこぼし | Part 2 | BM25 + dense hybrid + RRF |
| C-1 | 引用喪失 | Part 3 | citation 設計 / Anthropic Citations API |
| C-2 | context 爆発 | Part 3-4 | reranker で k を絞る + Part 4 で測定 |
| (運用全般) | 劣化への追従 | Part 5 | logging safety / drift / cost / index 鮮度 |
「動いているように見えるが、何が動いているかは検証していない」
ここまでの実装には 致命的な欠陥 があります。わたしたちは、いま動いているかどうかを 1 度も測定していません。
§3 で 4 つのクエリの代表例を見せましたが、それは恣意的な選別です。本当に動く RAG にしようとするなら:
- Faithfulness: 答えが retrieved context に裏付けされているか
- Answer Relevance: 答えが質問への直接の答えになっているか
- Context Precision: retrieve した chunk のうち、答えに寄与したものの割合
- Context Recall: 答えに必要な事実が retrieve できた割合
の 4 つを数値で測定 する必要があります。これらは Part 4「評価」 でクライマックスとして扱います。Part 1-3 の改善のすべてが、Part 4 のスコア改善として 客観的に確認できる 構造を、シリーズ全体で目指します。
次の Part への準備
companion repo の part-01 tag は本記事の実装そのものです。clone して動かしながら、または読みながら、自分の手で「動くけど使えない」を体感してみてください。
ollama pull qwen3:8b && ollama pull qwen3-embedding:0.6bgit clone https://github.com/zawazawa5809/rag-fundamentals-companion.gitcd rag-fundamentals-companiongit checkout part-01uv sync --frozenecho "RAG_PROVIDER=ollama" >> .envuv run python -m examples.naive_rag --query "あなたの試したいクエリ"API キーを使いたい読者へ: companion repo は Anthropic Claude + OpenAI Embedding 経路も一級サポートしています。
.envにRAG_PROVIDER=anthropic_openaiと各 API キーを置けば切り替わります (Part 3 で扱う Anthropic Citations API は Anthropic 経路でのみ動作)。本シリーズ本文の数値は、誰でも 0 円で再現できる Ollama 経路で統一しています。
そして、自分なりに「これは使えないな」というクエリを 3 つ見つけたら、それを覚えておいてください。Part 2 で同じクエリを叩いて、改善を 数値ではなく感覚 で先に体験してから、Part 4 で 改善が本物だったか を測定する流れになります。
この Part で手元に残る成果物
「読んだ」ではなく「作った」で次に進むために、Part 1 を終えた時点で次が手元にあるはずです。
- corpus inventory(v0): 自分の corpus を「genuine / 旧版 / 表層 trap / 構造 trap / 雑 」にざっくり仕分けた台帳
- failure case list: 自分のクエリで観察した失敗を A-1 / A-2 / A-3 / B / C-1 / C-2 に分類したメモ
- 設計課題リスト: 上の 5 問(lifecycle / lexical / structural / evidence / evaluation)を自分の corpus に当てた答え
次の Part に進む条件
- 旧版 trap か表層 trap を 1 件以上、自分の corpus で再現 できた
- retrieve された top-k の中身を、自分の言葉で説明 できる
- 自分の corpus で status(active/archived 等)がどこに書かれているか を把握した(Part 2 で抽出する)
シリーズ全体: 使える RAG の作り方 — 測って・直して・運用する
次回 Part 2: 「Retrieval を真面目に — chunking と hybrid search で recall を数値改善する」
参考文献
Footnotes
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks — Lewis et al., NeurIPS 2020. RAG という用語の原典 ↩ ↩2
Retrieval-Augmented Generation for Large Language Models: A Survey — Gao et al., 2023 (随時更新)。Naive / Advanced / Modular RAG の分類 ↩
LangChain - Text splitters — chunking デフォルト値 ↩
LlamaIndex - Production RAG chunking — 跨ぎ問題と semantic chunking ↩
Qwen3 Embedding — qwen3-embedding ファミリの MTEB 多言語ランキングとスペック ↩
Anthropic - Use XML tags to structure your prompts — XML タグでの context 構造化指針 ↩
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks — Reimers & Gurevych, EMNLP 2019. sentence embedding の表層類似性質 ↩
The Probabilistic Relevance Framework: BM25 and Beyond — Robertson & Zaragoza。BM25 の同義語問題 ↩
Anthropic - Citations API — RAG grounding / citation 設計 ↩ ↩2
Anthropic - Context windows — long context の trade-off ↩