
Retrieval を真面目に — chunking と hybrid search で recall を数値改善する
2026-05-24 改訂: 本シリーズは Ollama + Qwen3 で完全ローカル再現できる構成に作り直しました。本文の検索スコア・top-5 はすべて
qwen3-embedding:0.6b+rank-bm25で 実測した値 です。題材は架空企業「ナギサ・パートナーズ」(中堅 SIer、自社 SaaS「Mirage」を運用) の社内 wiki です。
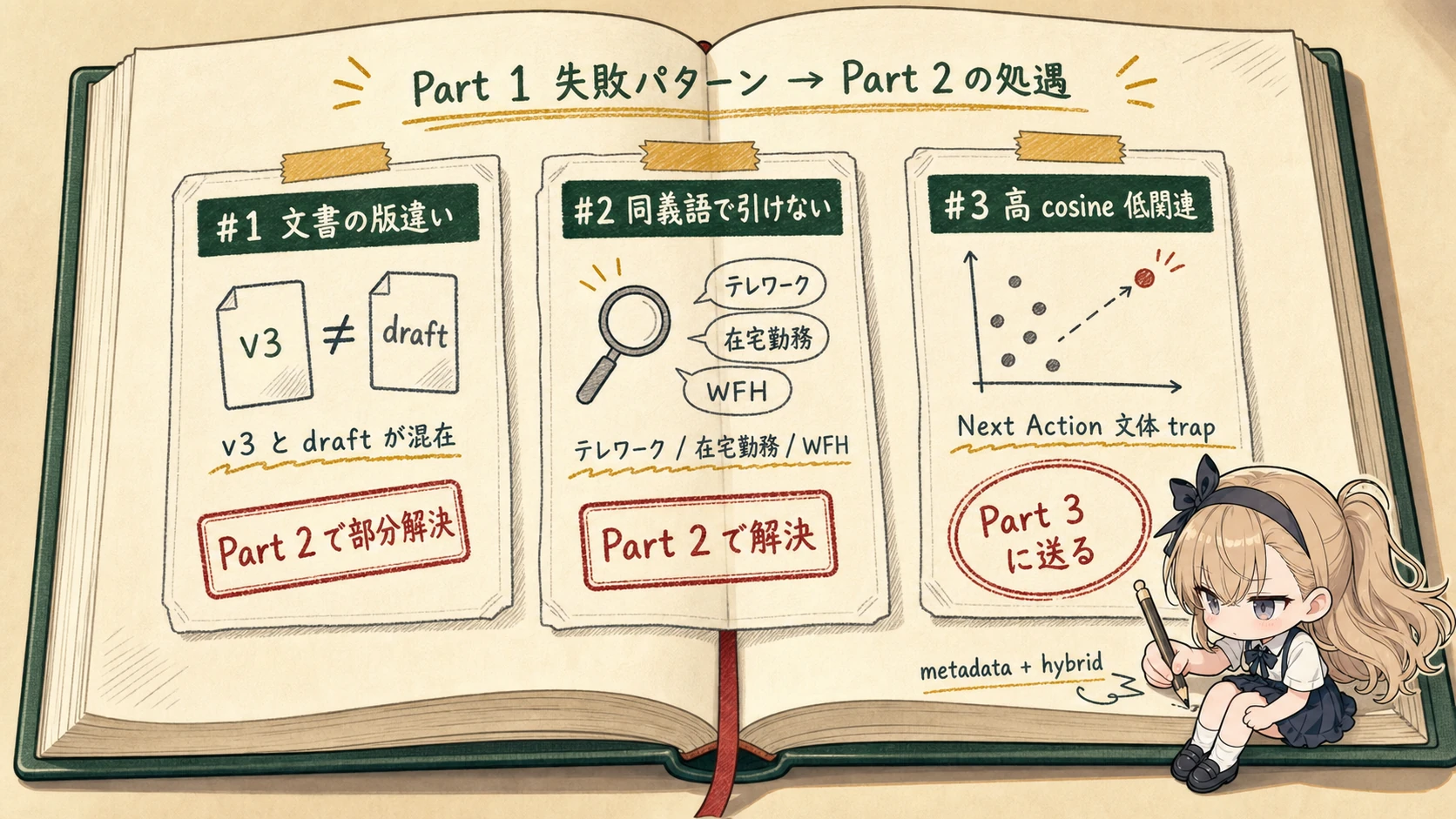
Part 1 では 100 行強の素朴な RAG が「動くけど使えない」ことを観察し、失敗を 3 グループに整理しました。本記事 (Part 2) はそのうち グループ A-3 (古い記述トラップ) と グループ B (同義語で取りこぼし) を retrieval 側の打ち手で改善します。テーマを一言で言うと 「chunk を整える + 検索方法を 1 つに頼らない」 の 2 軸です。表層・構造の trap (グループ A-1 / A-2) は本 Part の最後で「retrieval だけでは届かない天井」として再確認し、Part 3 の cross-encoder reranker に送ります。
現在地 — フェーズ 1「retrieval を立て直す」
- 前回まで動いているもの: 固定長 chunk + dense + top-k generation の 100 行 RAG。
- まだ壊れているもの: archived 旧版が top-1 に来る / 同義語で正解を取りこぼす / 表層・構造 trap が混じる。
- 今回直す failure mode: 旧版混入(A-3)/ 同義語取りこぼし(B)/ chunk の出自が不明なこと。
- 今回は直さないもの:
status=activeな意味的 trap(A-1/A-2)→ Part 3 へ。citation の信頼性 → Part 3。本番ログ・PII → Part 5。- 今回の合格条件: archived chunk が top-5 から消える / 現行 v3 chunk が上位に集まる。ただし active な trap は残ることを確認 する(それが Part 3 の入口)。
なぜ Part 1 の retrieval は限界だったのか
Part 1 の naive_rag.py を構造として眺め直すと、retrieval 側の欠陥は 3 点に集約できます。固定長 chunk・dense 一本足・metadata 欠落。それぞれが Part 1 で観察した失敗に直結していました。
固定長 chunk が壊すもの
Part 1 では 600 文字 / overlap 100 の sliding window で chunk を切っていました。これは 見出しを跨いで切る 事故を平気で起こす方式で、mirage-architecture-v3#04 のような chunk_id をログで見ても どの節の話か分かりません。社内ナレッジボットが「mirage-architecture-v3#07 を根拠に答えました」と言っても、人が裏取りするには結局該当ドキュメントを 1 から読み直すことになります。
chunk は本来「文脈の境界」を尊重すべきです。Markdown には #, ##, ### という機械可読な構造境界があるのに、固定長 split はそれを無視します。
dense 一本足の盲点
qwen3-embedding:0.6b の cosine 類似度は強力ですが、表層構文の影響を強く受ける ことが Sentence-BERT の研究 1 以来繰り返し報告されています。これは Part 1 のグループ A (表層・構造の trap) の理論的背景でもあります。
実務的に困るのはグループ B の方です。社内文書には「リモートワーク」「テレワーク」「在宅勤務」「WFH」のような 同義語が大量に並びます。クエリと corpus が表層で噛み合わないと、cosine がぎりぎり top-k 圏外に落ちる現象が頻発します。
metadata が消える
corpus の元 markdown には、人が読めば見える metadata があります。Part 1 で観察した mirage-architecture-v2-archive.md の冒頭には:
> ⚠️ Archive 注記: この設計書は 2023 年 9 月時点の v2 アーキテクチャを記録したもの。> 2025 年 3 月の v3 移行で全面刷新され、現行は mirage-architecture-v3.md。> 本書類は履歴参照と移行コンテキストの記録のために archive されています。一方、現行 mirage-architecture-v3.md の冒頭は:
> 最終更新: 2025 年 3 月 18 日 (プロダクト本部 / SRE 室レビュー済)> v2 → v3 移行完了、本番稼働中。人が読めば「片方は archive 済の旧版」と一瞬で分かります。けれど Part 1 の chunker は本文だけを embed して この『archive 済』という status を完全に捨てて いました。だから dense 検索は「Mirage アーキの認証」というクエリに対して、表層語が濃い 旧版 v2 を平気で top-1 に出した (Part 1 §3.2)。status を chunk に残しておけば、後段で「archived は検索結果から外す」ことができたはずです。
ここから先は、この 3 つの欠陥を順に潰します。
metadata 保持型 chunking
最初の打ち手は chunking の方針転換 です。意味境界を尊重し、出自 (status) を残します。これだけでグループ A-3 (古い記述) は 部分解決 します。
chunking の正しい目標
「chunk_size はいくつが良いか」は実は二次的な問題です。LlamaIndex の production RAG ガイド2や LangChain のドキュメンテーション3が一貫して強調するのは、chunk に metadata を残し、検索後に filter / grounding に使う こと。chunk_size=512, overlap=64 を魔法の数字のように扱う記事が多いですが、社内 wiki のような構造化ドキュメントを相手にする場合、chunk の境界は heading 階層で決め、長すぎる場合だけ二次分割する のが正解です。
heading-aware splitter の実装
companion の examples/retrieval/chunker.py で書いたのが以下の方針です (要点抜粋、全体は part-02 tag)。
def _split_by_headings(body: str) -> list[tuple[list[str], str]]: """Return [(heading_path, section_text), ...]""" matches = list(_HEADING_RE.finditer(body)) sections, path = [], [] for i, m in enumerate(matches): level = len(m.group(1)) # '#' の数 title = m.group(2) while len(path) >= level: path.pop() path.append(title) start = m.end() end = matches[i + 1].start() if i + 1 < len(matches) else len(body) sections.append((list(path), body[start:end].strip())) return sectionsここでのポイントは heading_path をリストとして保持 していることです。chunk_id を {doc_id}#{heading_slug}#{seq} 形式にすると、mirage-architecture-v3#認証#00 のように どの節の話かが ID だけで分かります。Part 1 の mirage-architecture-v3#07 との情報量の差は大きいです。
もう一つの細かい工夫は、heading の text を chunk 本文の先頭に prefix する ことです。これを忘れると、「在宅勤務手当」のように 見出しにしか出てこない語 が embed / BM25 から消えてしまい、クエリの「手当」と body 内のテキストが全く一致しなくなります。15 docs はこの heading-aware 方式で 118 chunk になります (Part 1 の固定長 47 chunk より細かく、節単位で揃う)。
LangChain の MarkdownHeaderTextSplitter3 を直接使う選択肢もありますが、本シリーズでは「ライブラリの中で何が起きているか」を読者が読めるよう、minimal 実装を companion に置きました。実プロダクションでは LangChain か LlamaIndex の階層的 node parser をそのまま使ってください。
corpus 側の status を救い出す
本シリーズの corpus は YAML frontmatter ではなく blockquote に metadata が書かれています。これは「整然とした corpus が前提」では困る現実 — 社内 wiki は人が手書きするので、metadata はだいたい blockquote か脚注に散らばっています。
chunker 側で正規表現で拾い出します。重要なのは status (active / draft / archived) の判定です:
_DRAFT_WORDS = ("承認されていない", "ドラフト", "draft v")# 旧版の「自己ラベル」だけを拾う。現行 doc が「v2 は…に archive 済」と# 参照するケース (mirage-architecture-v3) は active のまま残す。_ARCHIVE_WORDS = ("Archive 注記", "archive されてい")
def _status(bq: str) -> str: if any(w in bq for w in _DRAFT_WORDS): return "draft" if any(w in bq for w in _ARCHIVE_WORDS): return "archived" return "active"抽出結果: mirage-architecture-v2-archive.md → status="archived"、mirage-architecture-v3.md → status="active"、nagisa-expense-2023-archive.md → status="archived"。_ARCHIVE_WORDS を 自己ラベル (「Archive 注記」) に限定しているのがミソで、現行 v3 が本文で「v2 は…に archive 済」と 参照 していても、v3 自身は active のまま残ります。version 番号は blockquote に書かれていないことも多いので、ここでは無理に取らず、確実に取れる status を主役 にします。
version filter / status filter の実演
chunk に status が残れば、retrieval 後段で機械的に絞り込めます。
def apply_status_filter(indices, chunk_meta, *, exclude): return [i for i in indices if chunk_meta[i].get("status") not in exclude]exclude={"draft", "archived"} を与えると、mirage-architecture-v2-archive.md の chunk は 必ず除外 されます。Part 1 §3.2 で観察した「現行アーキを訊いたのに旧版 v2 が top-1 に来る」現象が、構造的に消えます。これがグループ A-3 の 部分解決 です。
残る課題 — Part 5 への送り
「これで版の混乱は終わり?」と聞かれると、半分 yes / 半分 no です。
status filter で落とせるのは 明示的に archive された文書 だけです。けれど現実には「status=active のままだが、内容が古びていく文書」があります。たとえば現行 mirage-architecture-v3.md も、いつか v4 が出れば「active だが古い前提を語る文書」になります。
この 「古いが現行扱いの文書をどう退役させるか」 は freshness filter (更新日 + ownership + 定期確認) と index 更新ポリシーの話で、Part 5「本番運用」のクライマックスとして扱います。本 Part では「status を chunk に残し、明示 archive を外す」ところまで進めます。
そのまま貼るテンプレート — chunking / metadata policy
ここまでの決定は、コードに散らばらせず 1 枚の policy 文書に固定しておくと、レビューでも引き継ぎでも効きます。次のテンプレートをコピペし、{ } の箇所を自分の corpus の答えで埋めてください。値はナギサ corpus での記入例です。
## chunking / metadata policy (v1)- 分割単位: Markdown 見出し (H2/H3)。1 chunk が {1,200} 字を超える場合のみ段落で二次分割- chunk_id 形式: {doc_id}#{見出し slug}#{seq}- 見出し prefix: chunk 本文の先頭に見出しテキストを付与する (見出しにしか無い語を検索可能にするため)- 保持する metadata: status (active/draft/archived/stale), updated_at, owner- status の出どころ: {frontmatter の status キー。無ければ blockquote の「Archive 注記」を正規表現で拾う}- 抽出ルールの注意: {archive の自己ラベルだけ拾う。他文書からの参照 (「v2 は archive 済」) は対象外}- retrieval 時の既定 filter: exclude = {draft, archived}- 例外: {法務クエリでは draft も検索対象に含める、等があれば書く}「status の出どころ」を 1 行で書けない corpus は、metadata がまだ整理されていない証拠です。その場合は filter の導入より先に、Part 1 の corpus inventory に戻って台帳を埋めるほうが効きます。
Hybrid search — BM25 + dense + RRF
2 つ目の打ち手は 検索方法を 1 つに頼らない こと。dense (embedding) と sparse (BM25) を並行で走らせ、結果を Reciprocal Rank Fusion で合成します。
なぜ dense だけでは足りないか
dense embedding は「意味類似」を捉える強さがありますが、同義語 / acronym / 表記揺れ過密ドメイン で挙動が不安定になります。「テレワーク手当」というクエリで、corpus 側は「在宅勤務手当」と書いている — この種のミスマッチで cosine がぎりぎり top-k 圏外に落ちる現象です。
近年の production レポート4では、「専門用語密度が高く同義語が多いクエリでは、BM25 は今でも dense に勝つ」と報告されています。dense と BM25 を 対立 として捉えるのではなく、両方の集合を取る という発想が正しいのです。
BM25 を最小実装で足す
BM25 自体は枯れた技術です。rank-bm25 ライブラリ5の BM25Okapi をそのまま使います。
from rank_bm25 import BM25Okapi
_LATIN_RE = re.compile(r"[A-Za-z0-9]+")_JA_RUN_RE = re.compile(r"[一-龯ぁ-んァ-ヴー]+")
def tokenize(text: str) -> list[str]: text = text.lower() tokens = _LATIN_RE.findall(text) # overlapping Japanese 2-gram — 「手当」「ク手」のような連接トークンを両方拾うため for m in _JA_RUN_RE.finditer(text): run = m.group() tokens.extend(run[i:i+2] for i in range(max(len(run) - 1, 1))) return tokens日本語は空白分割が効かないので、ラテン語の単語 + 日本語連続文字列の overlapping 2-gram で代替します。re.findall(r".{2}") で取ると non-overlapping (テレ / ワー / ク手 / 当 で「手当」が消える) になるので、finditer でラン単位に拾ってから 1 文字ずらしながら 2 文字ずつ取る形にしています。MeCab や Sudachi で形態素解析する手もありますが、依存を増やす価値があるかは「実 corpus で recall を測ってから決める」べきです。
念のため: rank-bm25 は教育目的で十分ですが、本番のスピードを求めるなら 2024 年に出た bm25s6 が SciPy sparse 行列ベースで桁違いに速いです。
スコアは合成できない、ランクなら合成できる
ここが本 Part の核心です。dense (cosine) と BM25 のスコアは 値域が違う:
- BM25:
0 ≤ score < ∞(IDF-weighted term frequency の和) - cosine:
-1 ≤ score ≤ 1
raw 加算は不可能です。「BM25 が 12.0、cosine が 0.85」を足しても意味のある値になりません。
これを解くのが Reciprocal Rank Fusion (RRF)7。Cormack らの SIGIR 2009 論文がオリジナルで、各 retriever の 順位 だけを使う score-agnostic な手法です:
def rrf_fuse(rankings: list[list[int]], *, k: int = 60, top_k: int = 5) -> list[int]: scores: dict[int, float] = {} for ranking in rankings: for rank, idx in enumerate(ranking): scores[idx] = scores.get(idx, 0.0) + 1.0 / (k + rank + 1) return sorted(scores, key=lambda i: -scores[i])[:top_k]k はスムージング定数で、論文の経験値は 60。k=10 でも k=60 でも順位はほぼ変わらないので、ここで悩む必要はありません。15 行未満で実装でき、現代の vector DB (Weaviate, Pinecone, Elastic 等) も hybrid search のデフォルト fusion 戦略として RRF を採用しています。
ドメイン依存の正直な話
「常に hybrid が勝つ」とは言いません。専門用語密度が低く、同義語が少ないドメインでは BM25 を足す価値が薄いことが報告されています4。本シリーズの corpus は 教育目的で意図的に同義語と版違いを仕込んで あるので効果が見えやすい設計です。実プロダクトでは、自分のドメインで小規模 golden set を作って「BM25 を足して本当に recall が上がるか」を測ってから入れる方が良いです。
自分の案件で hybrid を入れるべきか — 判断基準
「とりあえず hybrid」も「dense だけで十分」も、案件を見ずに決めると外します。次の判断表を自分のコーパスに当ててください。
| hybrid(BM25+dense)を入れるべき | dense only でよい / 後回しでよい |
|---|---|
| 専門用語・略語・型番・制度名が多い | corpus が小さく語彙が安定している |
| 同義語・表記揺れが多い(リモワ/在宅/WFH) | query と文書の語彙がかなり一致している |
| dense だけだと正解が top-10 ぎりぎりに落ちる | latency / 実装複雑性を最小化したい PoC 初期 |
| keyword の exact match が業務上重要 | (上のどれにも当たらない) |
迷ったら 「自分のドメインで小規模 golden set を作り、BM25 を足して recall が上がるか測る」 が唯一の正解。これは Part 4 で作る golden set が retrieval 設計にも効く、という伏線でもあります。
実測 — status filter は top-5 をどう変えるか
ここまでの打ち手 (heading-aware chunking + hybrid + status filter) を、Part 1 baseline と比較します。qwen3-embedding:0.6b + rank-bm25 で実測した値です。
recall@5 は飽和する — だから「汚染度」を見る
最初に正直な話をします。この 15-doc・教育用 corpus では、recall@5 (正解 doc が top-5 に入るか) はほぼ常に 1.00 に飽和 します。baseline でも hybrid+filter でも、正解 doc 自体は top-5 のどこかには入ります。だから「recall が 0.2 → 1.0 に跳ねる」という派手なグラフにはなりません (大規模 corpus なら recall は効く指標ですが、ここでは天井に張り付きます)。
差が出るのは top-5 の “汚染度” です。Part 1 §3.2 の Q1「Mirage 現行アーキの認証経路は?」で見てみます。
[Q1] Mirage 現行アーキテクチャの認証経路は?
baseline (dense top-5): mirage-architecture-v2-archive#認証-v2#00 status=archived ← 旧版 mirage-architecture-v2-archive#...旧版#00 status=archived ← 旧版 mirage-architecture-v2-archive#関連書類#00 status=archived ← 旧版 mirage-architecture-v3#...v3.2-現行#00 status=active ← 現行 (やっと 4 位) mirage-architecture-v2-archive#構成サマリ#00 status=archived ← 旧版
hybrid+filter (BM25+dense+RRF, exclude archived): mirage-architecture-v3#...v3.2-現行#00 status=active ← 現行 mirage-architecture-v3#認証#00 status=active ← 現行 mirage-architecture-v3#ロールバック手順#00 status=active ← 現行 mirage-architecture-v3#構成サマリ#00 status=active ← 現行 nagisa-incident-flow#関連書類#00 status=activestatus filter が stale chunk を浄化 — Q1「Mirage 現行アーキの認証」top-5 の内訳
Part 1 baseline は top-5 の 4/5 が旧版 (archived) で埋まる。Part 2 hybrid+filter は archived を全除外し、現行 v3 が top-5 を占める
baseline は top-5 のうち 4/5 が archive 済みの旧版 v2 です。正解の現行 v3 はやっと 4 位。LLM はこの context を渡されると、旧版の「BASIC 認証 + JWT」を答えてしまう危険が高いです (Part 1 §3.2 はたまたま正答しただけ)。
hybrid+filter では status filter が archived を 全部除外 し、top-5 が現行 v3 の節 4 つで埋まります。recall@5 はどちらも 1.00 ですが、generator が見る context の質は別物 です。この「context の純度」は Part 4 で Context Precision として数値化されます。
同義語クエリ (グループ B) はどうか
Q2「テレワーク手当はいくら?」は同義語デモです。corpus の見出しは「在宅勤務手当」で、本文の用語整理に「テレワーク」が併記されています。heading-aware chunking で見出し語が chunk に prefix されるため dense でも拾えますが、BM25 が「手当」のトークン一致で nagisa-remote-work をさらに安定して上位に固定します。dense 単独だと表記揺れで順位が動く一方、hybrid は BM25 の表層一致が錨になって順位が安定 します。小さな corpus では recall の数値差として見えにくいぶん、この「順位の安定」が hybrid の実利です。
なぜ Part 3 が必要か — retrieval を真面目にしても残る天井
retrieval を真面目にすると、版違い (A-3) と同義語 (B) は構造的に改善しました。けれど 表層・構造の trap (グループ A-1 / A-2) は hybrid+filter では落とし切れません。
天井の実例 — 意味的に近い trap は順位が下がらない
Part 1 §3.4 で見た「構造類似トラップ」の本丸を、Part 2 のパイプラインに通します。クエリ「Mirage 開発でコードレビューに必要な approve 数は?」に対する trap doc は nagisa-lt-evaluation (社内 LT 大会の「評価基準」。コードレビューの「評価」と意味的に近いが無関係)。
| stage | trap (nagisa-lt-evaluation) の順位 |
|---|---|
| Part 1: dense only | 4 位 |
| Part 2: hybrid+filter | 2 位 (悪化) |
| Part 3: + cross-encoder rerank | 9 位 (圏外へ) |
注目すべきは Part 2 で trap がむしろ 2 位に上がる ことです。BM25 が「評価」「基準」という表層語を強く拾い、RRF が dense と合算するので、意味的に近い trap は順位が下がるどころか上がってしまいます。status filter は archived は落とせても、active な trap には無力 です。
これが Part 2 の天井です。status=active で語も意味も近い trap は、dense でも BM25 でも RRF でも蹴り落とせません。Part 3 の cross-encoder reranker は、クエリと chunk を同時にエンコードして相互注意で再採点するので、この trap を 2 位 → 9 位まで突き落とせます (詳細は Part 3)。
もう 1 つの課題 — 引用喪失 (Part 3 で解決)
Part 1 で ### mirage-architecture-v3#00 のような chunk_id ラベルを context に入れたのに、生成側で chunk_id 参照が出力に残らない 現象を観察しました。retrieval を真面目にしても、「どの doc が根拠か」を読者が検証できないと社内ナレッジボットとして致命的です。「認証は Keycloak です」という回答が現行 v3 から来たのか旧版 v2 から来たのか — 一見同じでも信頼性が桁違いに違います。Part 3 で Anthropic Citations API と [citation: doc_id] 形式の grounding を設計します。
改善の検証は Part 4 に持ち越す
本 Part で見た「top-5 の汚染度」は目視の感覚値です。Part 4 では:
- 30 クエリ × 厳密 golden set
- RAGAs [Faithfulness / Answer Relevance / Context Precision / Context Recall] の 4 指標
- 「retrieve できたか」と「context を正しく使えたか」を分けて評価
を扱います。今回の「archived を落として top-5 を浄化した」効果は、Part 4 で Context Precision の改善 として数値に表れます。Part 1-3 の改善のすべてが Part 4 のスコアとして 客観的に 再確認される構造を、シリーズ全体で目指します。
companion repo と次回への接続
ollama pull qwen3:8b && ollama pull qwen3-embedding:0.6bgit clone https://github.com/zawazawa5809/rag-fundamentals-companion.gitcd rag-fundamentals-companiongit checkout part-02uv sync --frozenecho "RAG_PROVIDER=ollama" >> .envuv run python -m examples.retrieval.run # recall@5 + top-5 を観測uv run python -m examples.retrieval.run -q "あなたの試したいクエリ"Part 1 で「これは使えない」と感じた自分のクエリを Part 2 hybrid+filter で叩き直してみてください。top-5 から旧版や draft が消える はずです。そして「コードレビューの評価基準」のような 意味的に近い trap が残る 例も探してみてください — それが Part 3 で解く問題です。
この Part で手元に残る成果物
- chunking policy: 自分の corpus を「固定長で切るか / 見出しで切るか」を決め、chunk_id 命名規則(
{doc}#{節}#{seq})を定義した文書 - status 抽出ルール: 自分の corpus で active / draft / archived がどこに書かれているかを特定し、抽出する正規表現 or frontmatter キーを決めた
- retrieval log(top-5 汚染度): baseline と hybrid+filter で top-5 を並べ、どれだけ浄化されたかを記録した
- hybrid 採用判断: 上の判断表で「自分の案件に BM25 を足すか」を決めた(測ってから、が原則)
次の Part に進む条件
- 自分の corpus で status metadata を抽出 し、archived を top-5 から外せた
- それでも残る active な意味的 trap を 1 件以上見つけた(Part 3 で落とす対象)
シリーズ全体: 使える RAG の作り方 — 測って・直して・運用する
次回 Part 3: 「Generation を引用付きで書く — Anthropic Citations API と cross-encoder reranker」
参考文献
Footnotes
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks — Reimers & Gurevych, EMNLP 2019. sentence embedding の表層構文 bias (Part 1 でも引用) ↩
LlamaIndex — Production RAG — file_name / section / version 等の metadata を chunk に持つ意義と階層的 node parser の紹介 ↩
Markdown header metadata splitter — LangChain — 公式 docs。heading 階層を chunk metadata に伝搬する production パターン ↩ ↩2
Hybrid Search in Production: BM25 Still Wins on the Queries That Matter — 2026-04、BM25 が dense に勝つドメインの実証報告 ↩ ↩2
rank-bm25 · PyPI — 本記事で使った BM25 ライブラリ (BM25Okapi) ↩
BM25 for Python: BM25S — Hugging Face — 2024、SciPy sparse 行列ベースの高速 BM25 実装 ↩
Reciprocal Rank Fusion outperforms Condorcet and Individual Rank Learning Methods — Cormack, Clarke, Buettcher, SIGIR 2009. RRF 原典、k=60 の経験値とランクのみによる融合手法の証明 ↩